
목록ai (59)
운동하는 공대생
 [Deep Learning] GCN - Graph Convolution Network
[Deep Learning] GCN - Graph Convolution Network
1. Intro 이전에 GNN 에 대하여 글을 작성을 하였었지만 이번에는 GNN 을 이용한 가장 대표적인 모델인 GCN 에 대하여 이야기를 해보겠습니다. GCN - Graph Convolution Network는 이름에서 처럼 Graph 에 대한 데이터를 convolution 작업을 통해서 데이터를 모델에 전달하는 방식입니다. 2. Related Work 2.1 Graph 이전에도 이야기를 했지만 그래프 데이터의 구조는 기본적으로 노드(node) 와 간선(edge)들로 이루어져 있다. 그리고 이 노드들 간의 관계를 나타내는 방식이 Adjacency matrix(입접행렬)로 표현하면 노드가 간선으로 연결되어 있다면 1 아니면 0 으로 표시가 된다. 그리고 추가적으로 노드들의 정보 즉 데이터에 대한 부분은 ..
 [논문] InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
[논문] InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
논문 - https://arxiv.org/abs/2211.05778 InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state. This work presents a new large-scale CNN-based foundation model, termed arxiv.org 1. In..
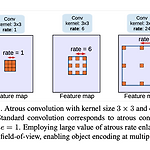 [논문]Rethinking Atrous Convolution for Semantic Image Segmentation(Deeplabv3)
[논문]Rethinking Atrous Convolution for Semantic Image Segmentation(Deeplabv3)
논문 - https://arxiv.org/abs/1706.05587v3 Rethinking Atrous Convolution for Semantic Image Segmentation In this work, we revisit atrous convolution, a powerful tool to explicitly adjust filter's field-of-view as well as control the resolution of feature responses computed by Deep Convolutional Neural Networks, in the application of semantic image segmentatio arxiv.org 1. Intro 기존의 컨볼루션 기반의 모델들은 지역..
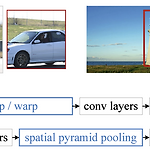 [논문] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
[논문] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
https://arxiv.org/abs/1406.4729v4 Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This requirement is "artificial" and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip th arxiv.org 1 Intro 논문에서 제시한 문제..
 [Deep Learning] GNN - Graph Neural Networks(미완)
[Deep Learning] GNN - Graph Neural Networks(미완)
1. Background Theories 1.1 Graph representation learning GNN 은 우리가 일상적으로 접하는 데이터중에서 데이터 간의 복잡한 관계를 표현하기에 위해서 등장한 이론이다. 예를 들어 소셜 네트워크, 웹 페이지 및 분자 구조 등이 그래프로 표현될 수 있다. GNN은 이러한 그래프 데이터를 분석하여 패턴, 상호 관계 및 특성을 발견하는 데 사용된다. 모델은 데이터 간의 관계를 이해하고 활용하는 데 사용되며 데이터 간의 상호작용까지도 그룹화가 가능해진다. 1.2 What is a graph? GNN에서 설명하는 그래프의 구조랑 노드(node)와 간선(edge)을 관계도를 말하는 자료구조를 말한다. 논문에서는 그래프를 G 그리고 그 안에 노드를 V 그리고 간선을 E라고 ..
 [Computer Vision] Semantic Segmentation
[Computer Vision] Semantic Segmentation
1. Intro Computer Vision에서 Object detection 다음으로 Semantic Segmentation와 Instance Segmentation 이 있다. 이것을 이미지에서 어떤 물체가 있는지를 탐지를 하는 것뿐만 아니라 이미지의 픽셀 단위로 어떤 부분이 분류한 물체가 있는지까지도 표시가 되는 장점이 있다. 2. Semantic Segmentation 2.1 Fully Convolutional Segmentation에서 가장 흔한 방식은 Fully Convolutional 방식이다. 이것의 구조로는 CNN의 convolutional layer 들과 downsampling과 upsampling을 포함하고 있다. downsampling 은 이전 CNN의 구조에서 처럼 Pooling의 ..
 [Computer Vision] Object Detection
[Computer Vision] Object Detection
1. Intro 이전까지 공부했던 내용에서는 CNN Layer를 활용하여서 이미지를 분류하였다. 하지만 최근 들어 이미지 데이터를 활용하여 분류하는 거뿐만 아니라 다양한 분야에서는 이미지 데이터를 활용한 모델들이 사용되고 있다. 공학적인 관점에서, 컴퓨터 비전은 인간의 시각이 할 수 있는 몇 가지 일을 수행하는 자율적인 시스템을 만드는 것을 목표로 한다 (많은 경우에는 인간의 시각을 능가하기도 한다). 그리고 과학적 관점에서는 컴퓨터 비전은 이미지에서 정보를 추출하는 인공 시스템 관련 이론에 관여한다. -위키백과 Computer Vision 은 그렇게 이미지 분류뿐만 아니라 이미지에서 물체를 탐지하는 Object Detection, 물체를 분류하는 Segmentation 등등 여러 태스크에서 활용이 되고..
 Automated Machine Learning (AutoML)
Automated Machine Learning (AutoML)
1. Intro 이번에 새로운 프로젝트로 AutoML에 대한 인프라를 구축하는 프로젝트를 시작하게 되었습니다. 그래서 이번에 프로젝트를 들어가기 이전에 내용을 한번 정리하고 AutoML에 대하여 간단하게 설명하겠습니다. 2. What is AutoML AutoML은 "Automated Machine Learning"의 약어로, 기계 학습 모델을 자동으로 만들고 최적화하는 기술을 말합니다. 이 기술은 인공지능 모델을 개발하는 데 필요한 일련의 과정을 자동화하여, 개발자가 더 적은 노력으로 더 나은 결과물을 얻을 수 있도록 합니다. AutoML은 전통적인 기계 학습 모델 개발 방법의 몇 가지 한계를 극복할 수 있습니다. 기존에는 데이터 전처리, 특징 추출, 모델 선택 및 하이퍼파라미터 튜닝 등 다양한 작업을..