
운동하는 공대생
[논문]Rethinking Atrous Convolution for Semantic Image Segmentation(Deeplabv3) 본문
[논문]Rethinking Atrous Convolution for Semantic Image Segmentation(Deeplabv3)
운동하는 공대생 2023. 7. 2. 19:34논문 - https://arxiv.org/abs/1706.05587v3
Rethinking Atrous Convolution for Semantic Image Segmentation
In this work, we revisit atrous convolution, a powerful tool to explicitly adjust filter's field-of-view as well as control the resolution of feature responses computed by Deep Convolutional Neural Networks, in the application of semantic image segmentatio
arxiv.org
1. Intro
기존의 컨볼루션 기반의 모델들은 지역적인 이미지 변환에 대한 불변성(invariance)을 갖는 경향이 있습니다. 이는 입력 이미지에 대한 작은 변화나 변형이 모델의 출력에 큰 영향을 미치지 않는 것을 의미합니다. 예를 들어, 객체의 크기나 위치가 조금 변해도 모델의 예측은 크게 달라지지 않습니다. 이러한 불변성은 객체 인식이나 분류와 같은 작업에서는 유용할 수 있습니다. 즉 이미지에 대한 작은 변화들은 convolution 작업이 진행되면서 차이를 인식하지 못하는 문제가 발생합니다.
이러한 문제를 해결하기 위해서 등장한 방식이 Atrous convolution입니다.

또 다른 문제는 탐지하려는 물체가 다양한 크기로 존재한다는 문제가 있습니다. 그래서 이 논문에서는 4가지 카테고리를 통해서 그 문제들을 해결했습니다.

2. Related Work
Image pyramid
모델을 다양한 scale의 이미지를 학습할 때 사용합니다. 이미지의 scale을 다양하게 조정하여서 모델에 이를 적용하기 위해서 feature를 추출하고 이후에 결합하는 방식으로 하나의 태스크 이미지에서도 스케일의 크기를 다르게 하여서 데이터를 처리하면 작은 scale에 대한 특징도 모델에 학습이 된다.
Encoder-decoder
2가지로 구성이 된다.
a) 인코더: 인코더는 feature map을 점차 줄여 나가면서 이미지 데이터의 특징을 유지합니다.
b) 디코더: 티코더는 a)의 방식의 반대로 인코딩 된 데이터를 더 큰 차원으로 다시 upsampling 해줍니다.
Context module
논문에서는 long-range context 즉 이미지 데이터 간 픽셀정보가 거리가 있어도 이것을 사라지지 않도록 하는 추가적인 처리 프로세스를 추가하였습니다.
atrous convolution 방식을 논문에서는 사용하는데 일정한 rate를 기준으로 떨어져 있는 픽셀 데이터를 pooling을 해줌으로써 픽셀의 거리가 떨어진 데이터끼리도 묶어서 특징을 추출하는 게 가능하다고 이야기를 합니다.
Spatial pyramid pooling
https://seungwoni.tistory.com/45
[논문] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
https://arxiv.org/abs/1406.4729v4 Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This requirement is "artificial" and may re
seungwoni.tistory.com
이전 글에서 간단하게 정리를 했지만 다양한 scale에 대한 convolution 이후의 fully connetec layer로 input으로 전환하기 위해서 고정된 사이즈의 크기의 bin 필터를 사용하여서 고정된 크기의 input vector를 만들어주는 게 목표입니다.
그래서 이 논문에서는 atrous convolution을 context module로 사용하고 SPP 방식을 툴로써 feature map에서 사용했습니다. 이것을 ASPP라고 이야기를 했습니다.
3. Method
3.1 Atrous Convolution for Dense Feature Extraction

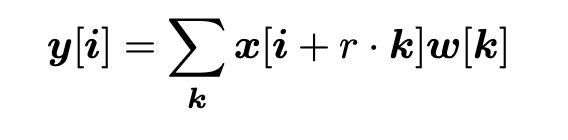
논문에서는 atrous convolutiond은 먼저 input featur map x와 output y라고 생각하면 i의 위치에 비율 r과 k 값을 곱한 위치와 필터 w의 값을 곱한 것의 총합이라고 볼 수 있는데 여기서 기존 convolution과 다른 점은 비율을 곱하여 input feature map의 곱하는 위치를 지정하는 것이다.
3.2. Going Deeper with Atrous Convolution
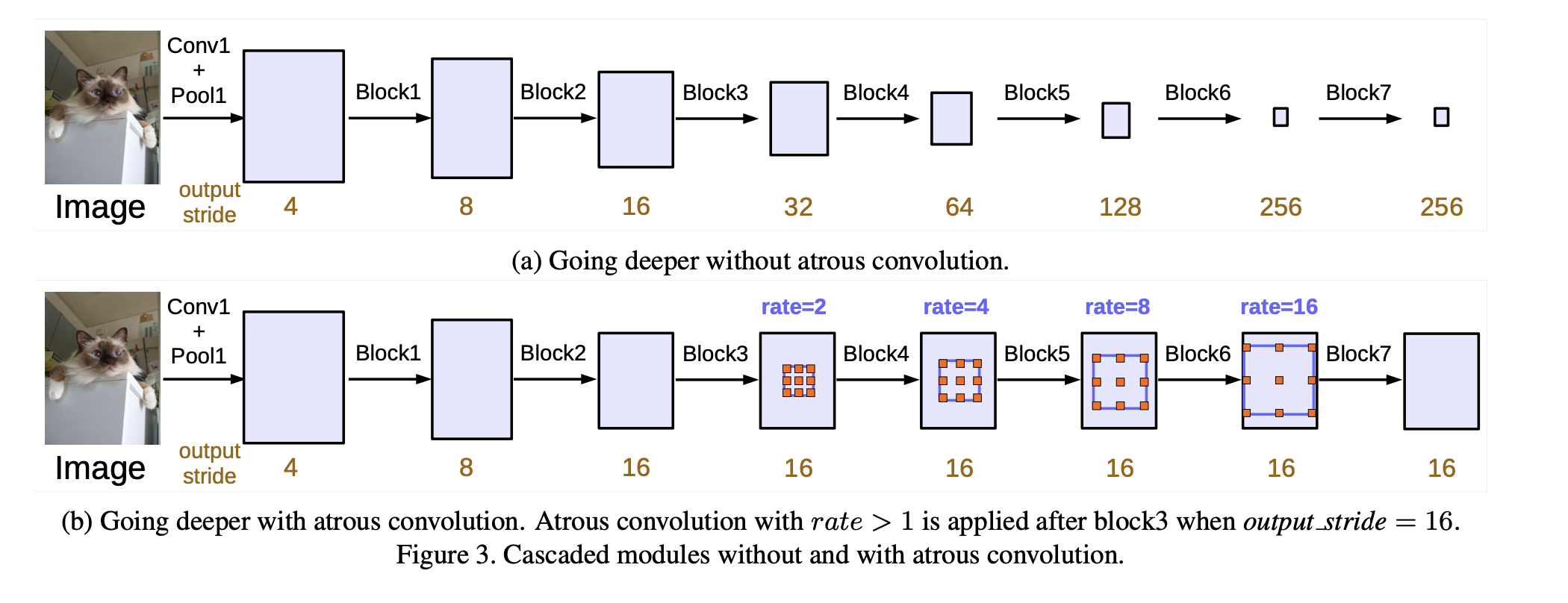
semantic segmentation에서는 지속적인 conv 작업은 부적절하다고 계속 이야기를 했다. 왜냐하면 semantic segmentaion은 픽셀 단위의 분류하여 object의 label을 분류해야 하지만 conv 작업과 pooling작업을 반복하면 이적의 경계가 모호해진다. 그래서 부적절하다고 볼 수 있다. 논문에서는 output stride에 따라서 연산하는 r (rate) 값이 달라진다고 했는데 논문에서는 16으로 고정을 하여서 2배씩 늘려 layer를 구성하였습니다.
output stride가 256이라는 것은 입력 이미지와 출력 특성 맵 간의 크기 비율을 나타냅니다. output stride가 256인 경우, 출력 특성 맵의 공간 해상도는 입력 이미지의 공간 해상도보다 훨씬 작아집니다.
이는 네트워크의 구조와 계산 흐름에 기인한 결과입니다. 딥러닝 모델에서는 일반적으로 특성 추출을 위해 여러 계층의 합성곱(convolution) 레이어를 거칩니다. 이 합성곱 레이어는 입력 이미지의 공간 해상도를 줄이는 연산을 수행하면서 특징을 추출합니다. 일반적으로는 pooling 레이어나 stride가 큰 합성곱 레이어를 사용하여 공간 해상도를 줄입니다.
output stride가 256이라는 것은 네트워크의 구조에서 stride가 큰 합성곱 레이어나 pooling 레이어가 여러 번 적용되어, 입력 이미지의 공간 해상도를 256배나 줄였음을 의미합니다. 이는 네트워크가 상대적으로 큰 수용 영역을 갖는 특성 맵을 생성하게 되는데, 이는 네트워크의 더 광범위한 콘텍스트 정보를 잡아내는 데 도움이 됩니다.
따라서 output stride가 256인 경우, 출력 특성 맵은 입력 이미지에 비해 공간적으로 상당히 축소된 형태를 가지며, 높은 수준의 추상화된 특징을 포착합니다. 이는 세그멘테이션 작업에서 세부 사항을 상실할 수 있으며, 따라서 보다 정확한 세그멘테이션 결과를 얻기 위해서는 output stride를 줄이는 방향으로 조정해야 합니다.
그래서 output stride의 크기는 사용자가 모델학습 속도를 계산하면 잘 조정을 해야 하고 값이 너무 크면 GPU연산 메모리 처리에 과부하를 준다고 합니다.
3.2.1 Multi-grid Method
dilation rate를 조절하는 하나의 방식으로 output stride로 각 atrous convolution에서의 rate 비율이 정해졌다면 이 값을 multi grid 방식을 통해서 같은 비율로만 곱하는 게 아닌 여러 비율을 가지고 적용을 시킵니다.
3.3. Atrous Spatial Pyramid Pooling
이전 ASPP 방식과 다른 적음 batch normalization을 추가를 했다는 게 Deeplabv2와 다른 점입니다. 그리고 여기서 문제가 하나 발생하는데 Multi-grid Method 방식으로 비율을 늘려가면서 conv 처리를 하는데 여기서 발생하는 문제는 거리가 있는 데이터의 정보도 같이 포함하여 feature map을 생성하고 싶어서였는데 너무 넓은 지역의 정보를 추출하면 원래 가지고 있던 작은 지역의 local 한 정보 까지도 의미가 퇴색된다는 문제가 발생합니다.
이런 문제를 해결하기 위해서 본 논문에서는 global context 정보 즉 global average pooling을 모델에 포함한다고 설명을 했습니다.
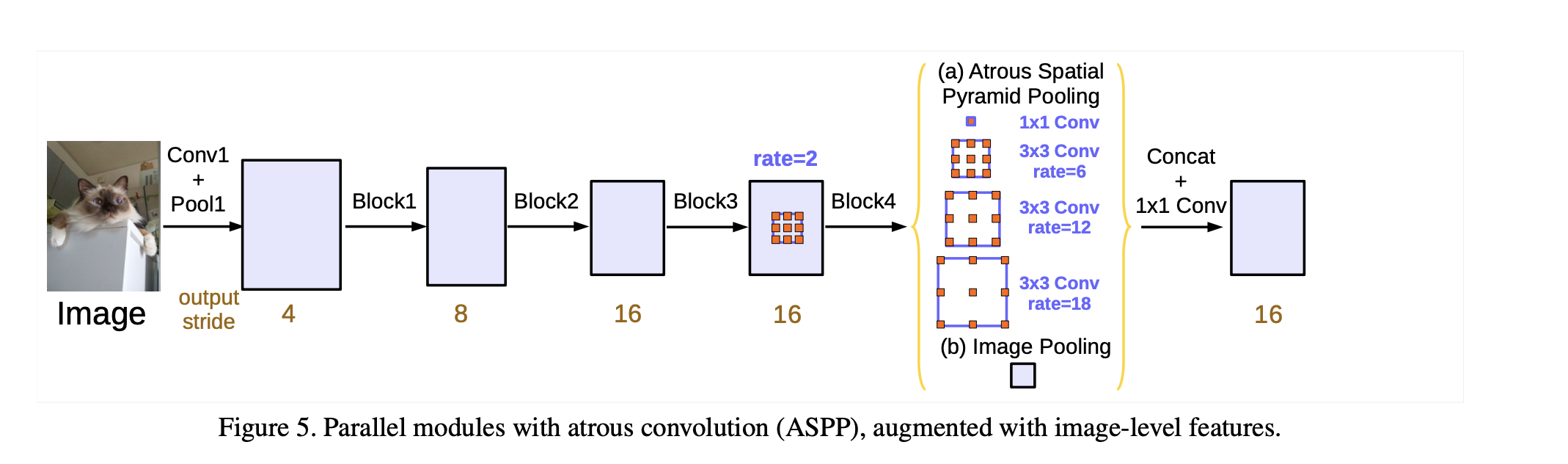
사진을 통해서 설명하면 1*1 conv 작업과 3*3 conv의 atrous convolution 작업을 병렬적으로 처리한 이후에 그것을 image-level features와 결합하고 이후에는 추가적으로 1*1을 한번 더 진행하여서 위의 문제를 해결하였다. 이전 버전과 다른 전음 output_stride를 기준으로 rate 가 변화한다는 것이고 1*1 convolution이 추가되었고 normalization 도 각각의 ASPP에 추가가 되었다.
- 각각의 convolution 연산을 거친 branch 들을 모두 concaternation을 하여 합친 다음, 마지막으로 1x1 convolution과 batch normalization을 거쳐서 마무리합니다.
- 각 branch들의 연산 방법과 branch들을 어떻게 concatenation을 하는지 정리하면 다음과 같습니다.
- ① = 1x1 convolution → BatchNorm → ReLu
- ② = 3x3 convolution w/ rate=6 (or 12) → BatchNorm → ReLu
- ③ = 3x3 convolution w/ rate=12 (or 24) → BatchNorm → ReLu
- ④ = 3x3 convolution w/ rate=18 (or 36) → BatchNorm → ReLu
- ⑤ = AdaptiveAvgPool2d → 1x1 convolution → BatchNorm → ReLu
- ⑥ = concatenate(① + ② + ③ + ④ + ⑤)
- ⑦ = 1x1 convolution → BatchNorm → ReLu



