
운동하는 공대생
[논문] InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions 본문
[논문] InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
운동하는 공대생 2023. 7. 3. 15:13논문 - https://arxiv.org/abs/2211.05778
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state. This work presents a new large-scale CNN-based foundation model, termed
arxiv.org
1. Intro

논문에서 저자는 기존 CNN 모델과 Vision Transformer의 차이점을 2가지로 이야기를 했습니다.
- 많은 양의 데이터에서 Vision Transformer(ViT)가 더 높은 성능을 보였다.
- convolution 하는 과정에서 직역적인 정보는 추출이 가능하지만 전체적인 정보를 담기는 어렵다. 커널의 크기를 들리더라도 한계가 분명 존재한다.(long-range dependence)
그래서 저자는 Interimage라는 새로운 방식을 도입했다고 설명했습니다. Interimage는 dynamic spars kernel을 사용하여서 기존 CNN의 단점인 long-range dependence를 만족한다고 했고 adaptive spatial aggregation 도 만족하며 또한 기존 커널 즉 3*3 정도의 기본 사이즈 커널을 사용함으로써 처리 효율까지도 효과적으로 처리가 가능하다고 말했습니다.
2. Related Work
2.1 Vision foundation models
CNN 모델이 점점 발전하면서 더욱 정교한 태스크에서 적용하는 게 가능해졌습니다. 그리고 ViT 모델 같은 경우에는 global attention을 탐색하여 인식하는 데는 도움이 되지만 transformer 특성상 모델의 크기가 상당히 커서 연산하는 시간과 cost가 많이 필요하다는 단점이 존재합니다.
2.2 Large-scale models
NLP 영역에서 Large-scale의 모델들이 꽤나 성공적인 성능을 보였습니다. 그래서 이런 파라미터를 더욱 많이 추가하여 모델의 성능을 높이려는 작업을 ViT 영역에서도 이루어졌으며 예시로 BEiT-3을 이야기했습니다. 하지만 CNN 분야에서는 아직 이런 방식이 조금 뒤처졌다고 저자는 말했고 이번 논문에서 CNN 구조의 모델을 ViT 모델의 정확도와 비교가 가능할 정도로 성능을 향상하는 게 목표라고 말했습니다.
3. Proposed Method
CNN 구조의 모델에서 large-scale CNN을 위해서라면 convolution 은 변형할 필요가 있습니다. 그것을 이 논문에서는 deformable convolution v2 (DCNv2)라고 부른다고 했습니다.
3.1 Deformable Convolution v3
3.1.1 Convolution vs. MHSA
먼저 convolution 과 MHSA (multi head self attention)의 차이점은 크게 2가지가 있습니다.
- Long-range dependencies : 앞서 이야기했던 것과 같이 3 * 3 convolution 같이 conv 작업을 수행하면서 Long-range에 대한 정보가 포함하지 못하는 경우들이 발생한다.
- Adaptive spatial aggregation : 이는 ViT와 CNN 사이의 trade-off를 나타내는 설명으로 해석될 수 있습니다. ViT는 대규모 데이터에서 보다 일반적이고 견고한 패턴을 학습할 수 있지만, 수렴 속도와 학습 데이터 요구량이 상대적으로 크다는 한계가 있습니다. 일반 컨볼루션은 더 빠른 수렴과 적은 학습 데이터 요구량을 가지지만, 일반적이고 견고한 패턴을 학습하는 데에는 제한이 있을 수 있습니다.
3.1.2 Revisiting DCNv2
논문에서는 ∆pk 을 통해서 offset을 convolution 작업 이후에 지정이 가능하도록 하여 Long-Range Dependencies를 극복했다고 말했습니다.
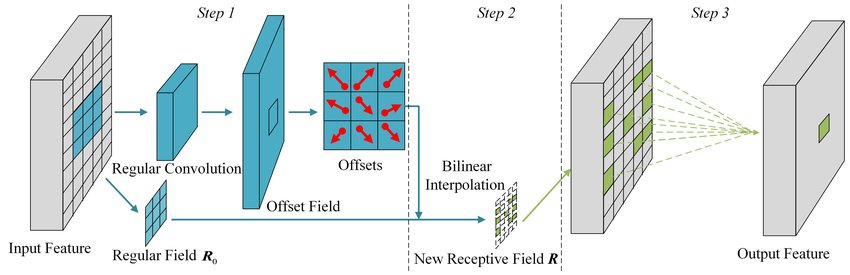
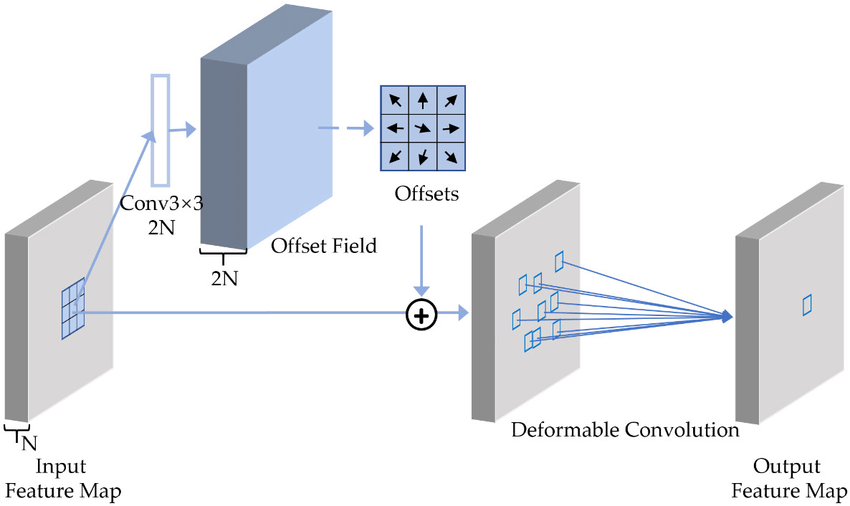
프로세스
1. 입력 Feature map을 입력으로 받습니다.
2. 입력 Feature map에 대해 3x3 컨볼루션 연산을 수행합니다. 이 컨볼루션 연산은 일반적인 컨볼루션과 동일한 방식으로 진행됩니다.
3. 3x3 컨볼루션 연산의 결과로 나온 특징 맵을 사용 하여 각 그리드 샘플링 위치에 대한 정보를 계산합니다. 이를 위해 두 가지 브랜치로 분기됩니다.
- 첫 번째 브랜치는 그리드 샘플링 위치에 대한 오프셋을 계산하는 데 사용됩니다. 이를 위해 3x3 컨볼루션 연산을 수행하고, 결과로 나온 특징 맵은 오프셋 필드를 나타냅니다.
- 두 번째 브랜치는 그리드 샘플링 위치에 대한 조절 필드를 계산하는 데 사용됩니다. 이를 위해 3x3 컨볼루션 연산을 수행하고, 결과로 나온 특징 맵은 조절 필드를 나타냅니다.
4. 계산된 오프셋 필드와 조절 필드를 사용하여 각 그리드 샘플링 위치에서의 오프셋 값을 계산합니다.
- 각 그리드 샘플링 위치에서의 오프셋 값은 해당 위치의 오프셋 필드 값과 조절 필드 값의 조합으로 결정됩니다.
- 보통은 bilinear interpolation을 사용하여 실수 값으로 오프셋을 보정합니다.
5. 계산된 오프셋 값을 사용하여 입력 Feature map의 각 위치에서 해당 위치의 값을 이동시킵니다.
- 이동된 특징 맵은 다음 계층으로 전달되어 추가적인 연산이나 처리를 진행할 수 있습니다.
이해가 어려웠던 부분
- offset field를 생성하는 conv 필터는 어떻게 지정되는가?
모델의 학습에 의하여 가중치들을 업데이트하면서 필터가 조정이 된다.
- 필터로 offset field를 만들고 나서는 offsets는 어떻게 결정되는 거야?
필터로부터 생성된 offset field는 각 그리드 샘플링 위치에 대한 이동량을 결정합니다. 이동량은 해당 위치에서의 오프셋 값으로 표현됩니다.
offset field는 학습된 필터와 입력 이미지의 특징 맵을 사용 하여 계산됩니다. 먼저, 입력 이미지의 특징 맵을 3x3 컨볼루션 연산을 통해 처리하여 두 개의 결과 특징 맵을 얻습니다. 하나는 오프셋 필드를 나타내고, 다른 하나는 조절 필드(modulation field)를 나타냅니다.
각 그리드 샘플링 위치에서의 오프셋 값은 해당 위치의 오프셋 필드에서 추출됩니다. 이를 위해 그리드 샘플링 위치에 대응하는 값을 offset 필드에서 가져옵니다. 예를 들어, 그리드 샘플링 위치가 (x, y)라면, offset 필드에서 (x, y) 위치에 해당하는 값을 가져옵니다.
- conv 작업을 하면 보통 그냥 숫자인 값일 건데 어떻게 이동량으로 나타내는 거야?
일반적으로 offset 값은 상대적인 이동량을 나타내는 벡터로 해석됩니다. 예를 들어, x와 y의 값이 (0, 0)이라면 해당 위치에서의 이동량은 없다는 것을 의미합니다. 만약 x가 양수이고 y가 음수인 경우 (1, -1), 이는 해당 위치에서 x축으로 1 단위만큼 양의 방향으로, y축으로 1 단위만큼 음의 방향으로 이동함을 나타냅니다. 따라서 offset 값은 그리드 샘플링 위치에서의 상대적인 이동량을 표현하는 것입니다.
또한, offset 값은 일반적으로 보간(interpolation)을 통해 실수형으로 변환됩니다. 보간은 이산적인 그리드 샘플링 위치에서의 값을 연속적인 위치로 확장하는 방법입니다. 예를 들어, 그리드 샘플링 위치가 정수 좌표인 경우, 이를 실수 좌표로 변환하여 부드러운 이동량을 나타내는 실수형 offset 값을 얻을 수 있습니다.
그래서 Bilinear interpolation 방식을 적용하여 처리합니다.
결국 grid sampling의 위치에 따라 각각 기준점 p0 의 값들의 먼저 conv 작업을 통해서 feature를 추출한 offset field를 생성하고 modulation field로 값을 가지고 오는 양을 조절하며 이 두 데이터 즉 field 데이터를 interpolation 방식으로 이동 거리로 변환하여 다시 다른 위치의 데이터를 convoluion을 진행하는 deformable convolution을 수행합니다. 그러면 이전에 말해던 CNN의 long-range dependence 를 해결하는 게 가능해진다.
(이렇게 이해함..)
3.1.3 Extending DCNv2 for Vision Foundation Models
- Sharing weights among convolutional neurons => 컴퓨팅 코스트 줄임
- Multi-group mechanism => 그룹별로 DCN을 나눠서 오프셋을 다양하게 가지고 간다.
- Normalizion modulation => sigmoid 가 아닌 학습에 좋은 softmax를 사용
3.2 InternImage Model
이제 DCNv3을 이용한 Interimage의 기본 구조에 대하여 설명을 하겠습니다.
3.2.1 Basic block
DCNv3을 구성으로 하는 basic block에서는 LN(Layer Normalization), FFN(Feed-Forward Networks), GELU(Gaussian Error Linear Unit), DCNv3을 포함하여 구성되었고 CNN의 bottlenecks현상을 해결하는 구조가 이난 ViT의 구조와 유사하게 구성하였다.
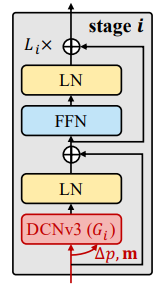
3.2.2 Stem & downsampling layers

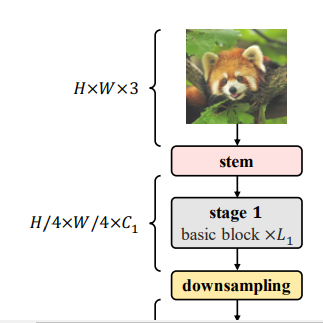
위의 사진과 같이 Stem 은 Basic block 이전에 위치하며 3*3 conv, LN을 거치게 된다. 그러면 이전에 입력을 받았던 feature map이나 사진은 4배가 줄어든다. downsampling layer도 마찬가지로 3*3 conv 작업을 진행하고 LN layer를 거침으로 2배 정도 작아지는 효과가 있다.
3.2.3 Stacking rules
Internimage에서 Stacking Rules(스태킹 규칙)이 필요한 이유는 여러 개의 이미지 스택을 처리하고 결합하는 과정에서 일관된 방식을 유지하기 위해서입니다.
Internimage는 이미지 스택을 생성하기 위해 여러 개의 이미지를 수직 또는 수평 방향으로 쌓는 작업을 수행합니다. 이때, 스택 내의 이미지들은 특정한 순서와 방향으로 결합되어야 합니다. 이를 위해 Stacking Rules이 사용됩니다.
Stacking Rules은 다음과 같은 역할을 수행합니다:
1. 순서 결정: 이미지 스택에 포함될 이미지들의 순서를 결정합니다. 즉, 어떤 이미지가 스택의 맨 위에 위치하고, 어떤 이미지가 그 아래에 위치할지를 정합니다. 이는 이미지 스택 내에서의 상대적인 위치를 결정하는 데 중요합니다.
2. 방향 결정: 이미지 스택의 이미지들이 수평 방향으로 정렬되는지, 아니면 수직 방향으로 정렬되는지를 결정합니다. 이는 이미지 스택의 구조를 결정하며, 후속 처리 및 분석을 수행할 때 필요한 정보를 제공합니다.
3. 일관성 유지: Stacking Rules을 사용하여 이미지 스택을 생성하면, 동일한 작업을 다른 이미지 스택에도 적용할 수 있습니다. 이는 일관된 분석 및 처리 과정을 보장하고, 다른 이미지 스택 간에 결과를 비교하거나 결합하는 데 도움을 줍니다.
따라서, Internimage에서 Stacking Rules을 사용함으로써 이미지 스택의 구성과 순서를 일관되게 유지할 수 있습니다. 이를 통해 이미지 스택을 처리하고 분석하는 작업을 효율적으로 수행할 수 있으며, 다른 이미지 스택 간에도 일관성 있는 결과를 얻을 수 있습니다.
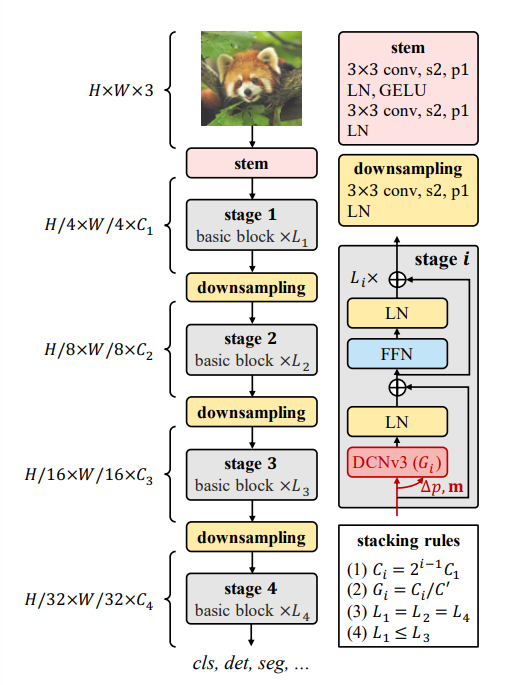
사진의 오른쪽 아래를 보면 stacking rules에 대한 내용이 있는데

(1) 채널의 수는 처음 입력받은 채널의 수 C1에 의하여 결정됩니다..
(2) 그룹 번호가 단계의 채널 번호와 일치하도록 합니다.
(3) & (4) 스테이지의 block의 수는 1,2,4 스테이지에서는 동일해야 하면 3번은 이것보다 크거나 같아야 한다.



