
운동하는 공대생
[논문] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 본문
[논문] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
운동하는 공대생 2023. 7. 2. 14:17https://arxiv.org/abs/1406.4729v4
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This requirement is "artificial" and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip th
arxiv.org
1 Intro
논문에서 제시한 문제 상황은 기존 CNN 모델에서 고정된 이미지로 변환을 하여 CNN 프로세스를 진행한다는 문제가 있다고 말했습니다. (e.g 224 * 224) 그렇게 된다면 이미지 자체에서 물체를 탐지하거나 인식할 때 외곡이 발생합니다.

사진과 같이 이미지를 Spatial pyramid pooling layer 를 이미지 conv layers 이후에 추가를 하여서 문제를 해결했습니다. 구조를 그럼 여기에 추가한 이유는 CNN 구조에서는 convolutional layer에서는 고정된 이미지의 사진이 필요하지 않기 때문입니다. 그래서 SPP layer에서 고정된 사이즈의 features를 output으로 하여 fully-connected layers에 전달하게 됩니다.
2 DEEP NETWORKS WITH SPATIAL PYRAMID POOLING
2.1 Convolutional Layers and Feature Maps
이전의 CNN 에서 convolutional layer는 이미지에서 convolution 작업을 진행하고 이것을 통해 feature map을 output으로 반환합니다. 이것은 이후에는 fully-connected layer에 고정된 사이즈의 벡터로 전달하게 됩니다. 하지만 사진의 설명처럼 기존의 수정된 사이즈의 사진을 통해서가 아닌 사진 그대로를 convolustion 해서 feature map을 추출하면 각각 사진의 처럼 상호 대응이 된다는 걸 알 수 있습니다. 이것은 사진의 이미지를 변환하지 않고 작업을 진행하는 게 의미가 있다는 걸 말해준다고 논문에서는 이야기했습니다.
2.2 The Spatial Pyramid Pooling Layer
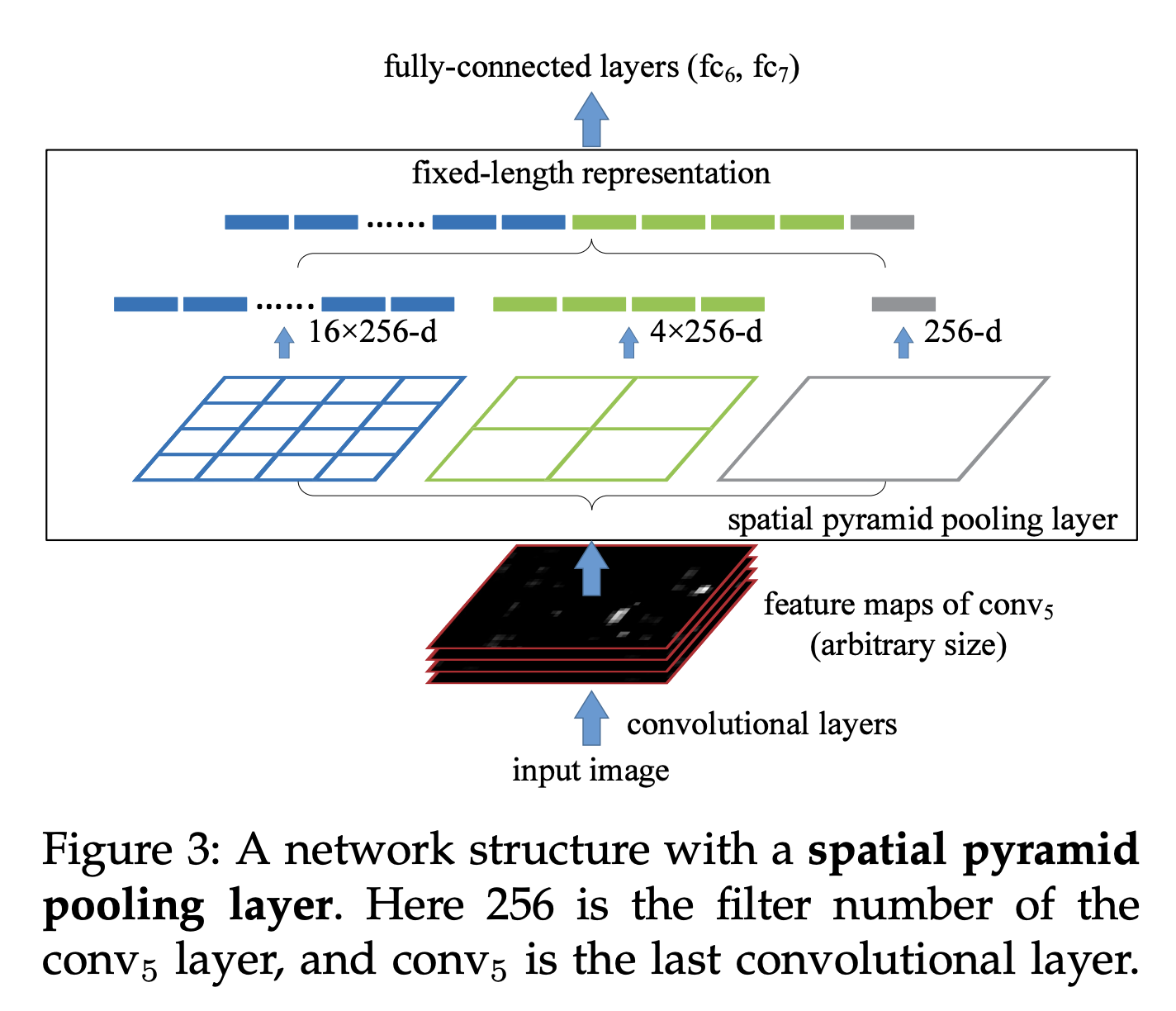
위의 그림은 SPP layer 의 작동 방식이다. feature map을 conv layer의 output으로 전달을 받았다면 이것을 SPP layer를 통해서 fully connected layer로 전달이 되게 됩니다. 여기서 고정된 크기(사용자가 지정 가능) 4*4, 2*2, 1*1로 나뉘는 각각 다른 pooling size로 max pooling을 진행하게 된다면 고정된 input을 원하는 fully-conneted layer의 조건과 그리고 여러 가지 scale에 대한 정보도 추출하는 게 가능하다고 합니다. 그리고 여기서 공간의 작은 단위( 1 * 1의 작은 단위 혹은 4*4에서의 한 칸)를 Bin이라고 합니다. 간단한 식으로 보게 된다면 conv layer에서는 한 개의 feature map은 임의의 크기로 구성이 된다면 (x) x*x*256 (사진의 예시처럼) 구성이 될 것이고 SPP layer를 거치게 된다면 각각의 feature map 은 SPP layer를 거치면서 21 * 256의 고정된 벡터로 변환이 됩니다.
2.3 Training the Network
Sing-size training: 앞에서 설명한 내용과 같이 학습 이전에 spp layer의 bin 의 사전에 정의하여서
Multisize training: resiz를 통해서 동일한 배치로 만들어서 학습을 진행하고 두 스케일에 대해서 같은 파라미터를 공유하도록 두 개의 네트워크를 학습시킴



