
운동하는 공대생
[Computer Vision] Object Detection 본문
1. Intro
이전까지 공부했던 내용에서는 CNN Layer를 활용하여서 이미지를 분류하였다. 하지만 최근 들어 이미지 데이터를 활용하여 분류하는 거뿐만 아니라 다양한 분야에서는 이미지 데이터를 활용한 모델들이 사용되고 있다.
공학적인 관점에서, 컴퓨터 비전은 인간의 시각이 할 수 있는 몇 가지 일을 수행하는 자율적인 시스템을 만드는 것을 목표로 한다 (많은 경우에는 인간의 시각을 능가하기도 한다). 그리고 과학적 관점에서는 컴퓨터 비전은 이미지에서 정보를 추출하는 인공 시스템 관련 이론에 관여한다.
-위키백과
Computer Vision 은 그렇게 이미지 분류뿐만 아니라 이미지에서 물체를 탐지하는 Object Detection, 물체를 분류하는 Segmentation 등등 여러 태스크에서 활용이 되고 있으며 Object Detection에 대하여 공부를 했다.
2. Object Detection
Object Detection은 먼저 이미지 데이터에서 데이터 안에 있는 물체를 탐지하는 태스크로서 RGB 이미지를 Input 데이터로 받으면 이것을 물체의 Label과 Bounding box를 탐지하는 방식이다. 이때 Label 이란 이미지에서 탐지한 물체가 어떤 물체인지를 표시하는 값으로 예를 들어 자동차를 탐지했다면 '자동차'라고 말해주는 물체의 카테고리를 분류해 주는 고정된 값이다. Bounding box는 탐지한 물체의 위치정보로 보통 x, y, width, height로 구성되며 물체에 대한 위치정보가 담겨있다.
Object Detection에서 반드시 태스크를 해결할때 발생하는 문제는
- Multiple outputs : 물체의 종류에 따른 여러 종류의 output
- Multiple types of output : 물체의 위치와 종류를 예측해야 하므로 여러 타입의 예측값
- Large images : 분류는 보통 224 * 224 에서 작동하지만 그것보다 큰 이미지에서 문제가 발생

물체를 한가지만 탐지한다고 한다면 위의 그림과 같은 프로세스를 통해서 물체를 이미지에서 탐지하는 게 가능하다 하지만 이미지에서는 여러 가지고 물체들을 탐지를 해야 하고 이것은 예측을 해야 하는 위치정보나 라벨값을 무수히 많이 예측을 해야 한다는 이야기이며 이것은 Object Detection에서 핵심 요소라고 할 수 있다.
2.1 Multiple Object Detecting - Sliding Window
Sliding Window 방식은 기존 CNN 모델을 활용하여서 일정 범위(bounding box)를 지정하고 이것을 CNN모델에 적용시켜 물체를 탐지하는 방식으로 일정 범위를 이동시켜서 여러 개의 물체를 탐지하는 방식이다. 하지만 이것의 문제는 일점 범위를 지정을 해야 하는데 이미지의 높이와 너비를 생각한다면 무수하게 많은 bounding box를 생성하고 대조해야 하는 문제가 발생한다.

수식으로 간단하게 환산하면 이렇게 이미지 사이즈 높이(H), 너비(W)에서 일정 범위를 지정하는 bounding box의 높이(h), 너비(w)라고 한다면 상당히 많은 box가 생기는걸 알 수 있다.
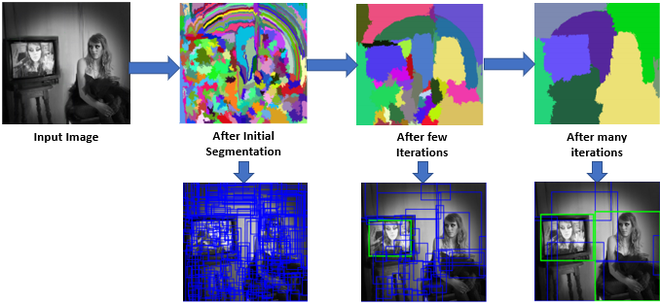
2.1.1 Region Proposals(지역 제안)
이전 방식에서 bounding box의 위치를 지정하는데 있어서 box의 후보군이 상당히 많이 발생하는 것을 알 수 있다. 그래서 이것을 해결하고자 나온 이론이 Region Proposals이라는 방식인데 물체를 한 번에 탐지하기 위해서 box를 물체가 다 들어가도록 지정하는 방식이다. 기본적일 이론은 이렇지만 최근 다양한 방식으로 box를 지정하는 이론들이 제시되고 있다. 그중 대표적으로 'selective search'방식을 예로 들면 후보군 box에서 greedy algorithm을 사용하여서 작은 후보 box를 색감이나 텍스처가 비슷한 큰 box로 결합시키면서 불필요하거나 겹치는 box를 하나씩 제거해 나가면서 최종적으로 물체를 다 담고 있는 box만 남도록 하는 방식이다.
2.2 R-CNN : Region-Based CNN
R-CNN 방식은 'selective search' 방식을 베이스로 하며 이미지를 CNN Layer와 결합하며 Proposal를 Label과 위치를 예측한다.
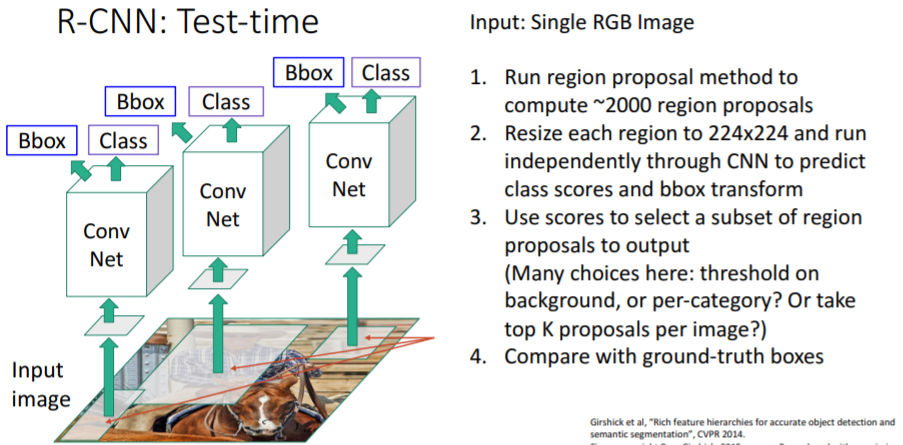
위의 그림은 R-CNN의 작동 순서이다. 먼저 RGB 이미지를 selective search 방식으로 proposal를 지정하고 이것을 224*224 이미지로 축소한 이후에 이것을 CNN Layer에 적용시키고 class와 위치를 예측한다.
2.3 Intersection over Union(IoU)
IoU는 예측한 이미지의 bbox위치가 정답과 얼마나 차이가 나는지를 보여주는 방식으로 물체의 예측된 위치와 물체의 원래 위치를 겹쳐서 비교하여 그것의 비율을 측정하고 비율을 통해 얼마나 정확도 있게 예측이 되었는지를 판단하는 게 가능하다.

- IoU> 0.5 : decent
- IoU> 0.7 : pretty good
- IoU> 0.9 : almost perfect
2.4 Overlapping Boxes - Non-Max Suppression(NMS)
Object detect 를 하면서 진행을 하다 보면 bbox가 겹치는 문제들이 발생한다. 그래서 이렇게 겹치는 문제를 제거해야 한다. 그래서 등장한 방식이 NMS방식이다.

순서대로 따라서 설명하면 먼저 가장 높은 점수의 box를 선택하고 이것을 겹치는 부분이 있는 box들과 비교한 이후에 IoU 방식을 사용해서 일정 임계치를 넘으면 overlapp 즉 박스가 겹치는 상황이라고 판단하고 이것을 제거(예시에서는 오렌지 박스제거) 하는 방식으로 진행한다. 그렇게 겹치는 부분을 제거했다면 다시 1번으로 돌아간다. 이런 과정을 반복하여 겹치는 부분의 박스들의 모두 제거하는 게 가능하다.
하지만 이런 방식에서도 명확한 한계가 존재한다. 탐지된 물체가 많을 때 한계가 발생한다. 탐지된 물체가 많으면 box가 상당히 많이 겹치는 문제가 발생하는데 이때 겹치는 부분도 많이 발생해서 물체를 잘 탐지를 했지만 다른 물체가 겹치는 box라고 착각하고 이를 제거한다면 물체를 잘 탐지했다고 하더라고 정확도가 낮아지는 문제가 발생한다.
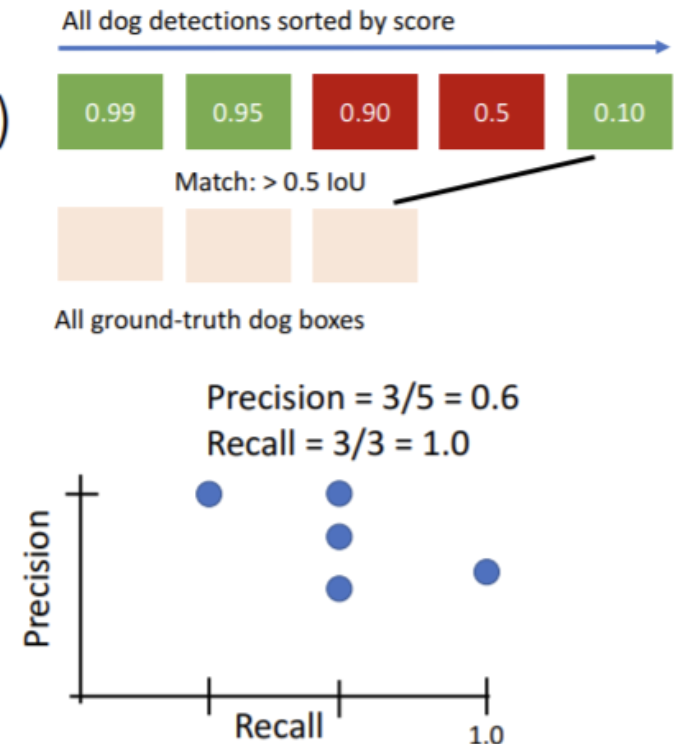
2.5 Evaluating Object Detectors : Mean Average Precision(mAP)

1. 이미지의 결과를 디텍터를 이용하여 도출한다 그리고 NMS방식으로 처리한다.
2. 각각의 카테고리별로( 강아지, 고양이, 차) box를 정확도(classification score : 이는 탐지를 잘 하건 안하건 예측한 모두를 포함)를 기준으로 정확도가 높은 순서로 정렬한다.
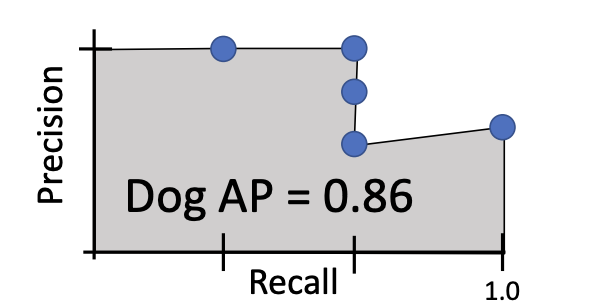
3. 그 이후에는 정답값 즉 탐지해야하는 한 카테고리(강아지) 안에서 탐지해야 하는 물체들과 전부 비교하여서 임계치(IoU 0.5)를 넘는다면 GT를 제거하고 아니면 negative로 두고 진행한다. 그렇다면 아래와 같이 정밀도(Precision), 재현율(Recall)의 값이 나올 것이며 이것을 그래프로 도식화하고 적분하여 평균을 구하면 이것이 한 카테고리에서의 AP값이 된다. 이것을 모든 카테고리를 분석하고 평균을 구하면 mAP가 된다.
2.6 Fast R-CNN
기존 R-CNN모델의 속도가 너무 느려서 이를 보안하고자 등장하였다.
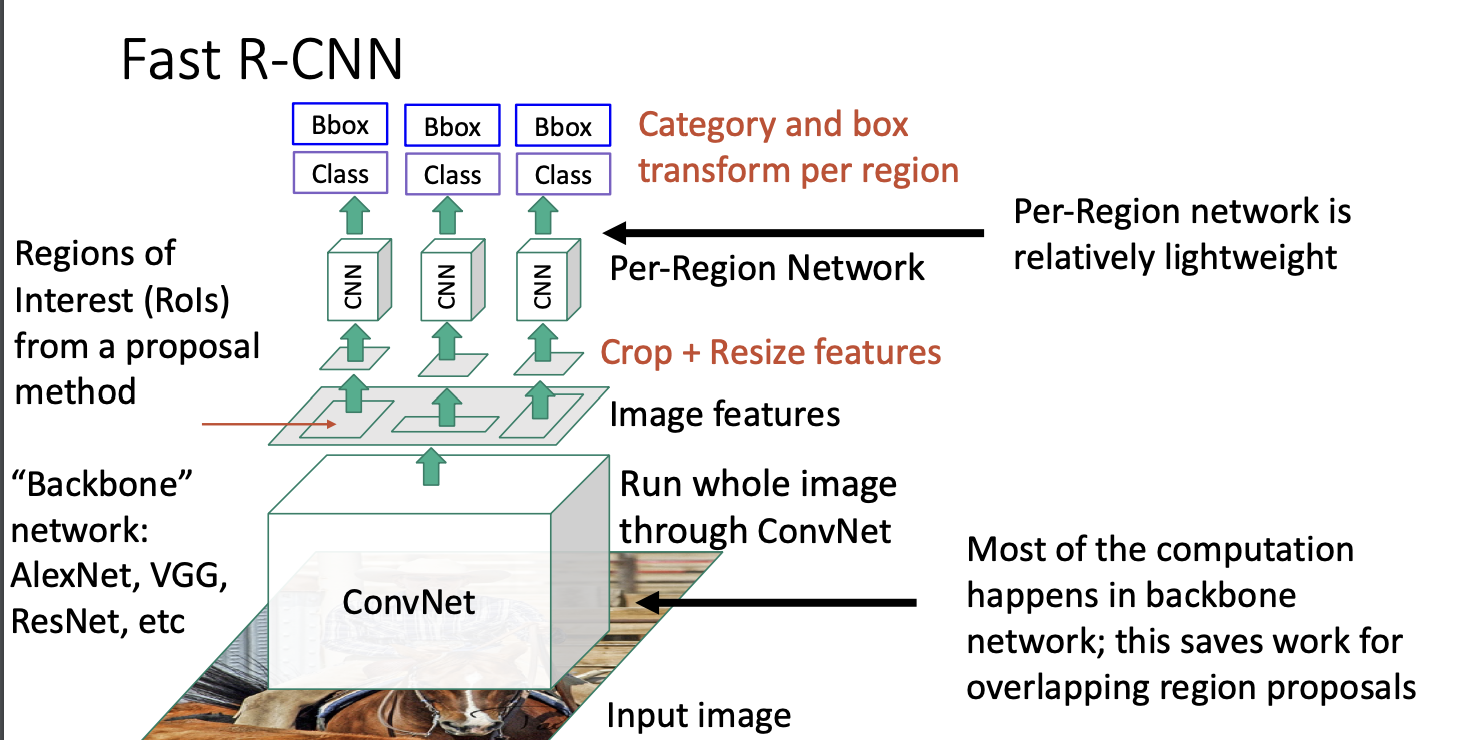
위의 사진과 같이 이미지 사진에서 Region Proposals 를 나눠서 모델에 적용시키는 방식이 아닌 이미지 전체를 먼저 ConvNet을 통해서 convolution 작업만 한 이후에 Region Proposals를 지정하고 이것을 이용하여 모델에 적용시킨다. 먼저 ConvNet을 진행하는 것을 "Backbone"이라고 한다.
2.6.1 Cropping Features : RoI Pool
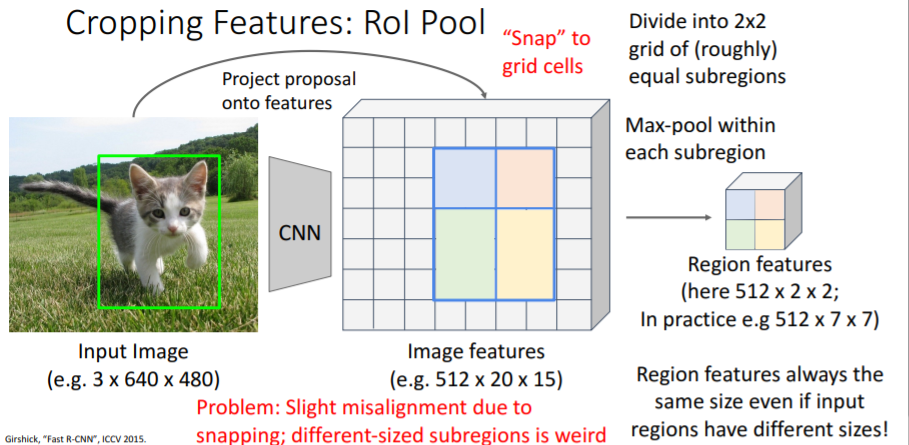
기존 이미지에서 proposal를 먼저 하고 물체의 위치를 지정하고 이후에 backbone을 진행한 feature map에서 snap방식을 통해서 기존에 box 위치를 feature map에 적용시키고 이것을 다시 2*2 정도로 roughly하게 나눠서 max-pool 방식으로 pooling을 진행한다.
2.6.1 Cropping Features : RoI Align
RoI Align은 객체 탐지 모델에서 Region of Interest(ROI)를 처리하기 위한 방법 중 하나입니다. RoI Pooling과 유사하지만 좀 더 정교한 방법으로 ROI 영역과 특성 맵을 매핑합니다.
일반적으로 특성 맵은 픽셀 단위의 좌표를 기준으로 구성되지만, ROI 영역은 픽셀 단위가 아닌 부동 소수점 좌표를 가지는 경우가 있습니다. 이러한 경우 기존의 RoI Pooling은 픽셀 단위로 정렬되어 매핑하기 때문에 정확한 위치 정렬이 어렵습니다.
RoI Align은 이러한 문제를 해결하기 위해 세밀한 위치 정렬을 수행합니다. 이를 위해 RoI 영역의 위치와 크기에 따라 특성 맵을 조정 하여 부동 소수점 단위로 정확한 위치 매핑을 수행합니다. 이를 통해 ROI 영역의 작은 변화에도 민감하게 반응할 수 있으며, 객체의 세부 정보를 보다 정확하게 추출할 수 있습니다.
RoI Align의 주요 아이디어는 ROI 영역을 일정한 크기의 그리드로 분할한 후, 각 그리드 셀의 위치에 대해 양선형 보관법을 사용하여 특성 맵 상의 실수 좌표에 대응하는 값을 구하는 것입니다. 이렇게 구한 값을 통해 정렬된 특성 맵을 생성하고, 이를 후속 네트워크 계층에 전달하여 객체 분류 및 경계 상자 조정을 수행합니다.
RoI Align은 RoI Pooling과 비교하여 위치 정확도가 높고 세밀한 특성 맵을 생성할 수 있어, 객체 탐지 모델의 성능을 향상할 수 있는 중요한 기술입니다.
-gpt
2.7 Faster R-CNN
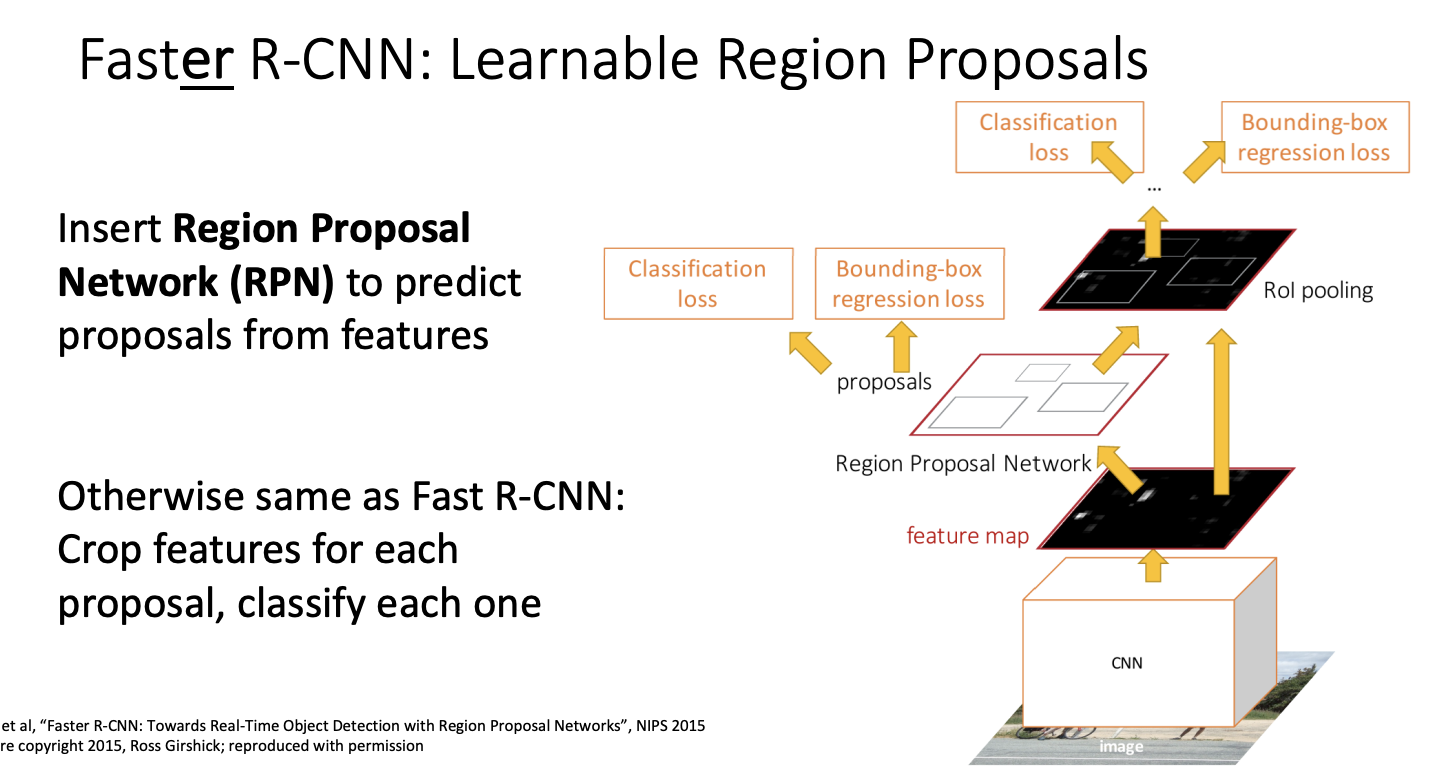
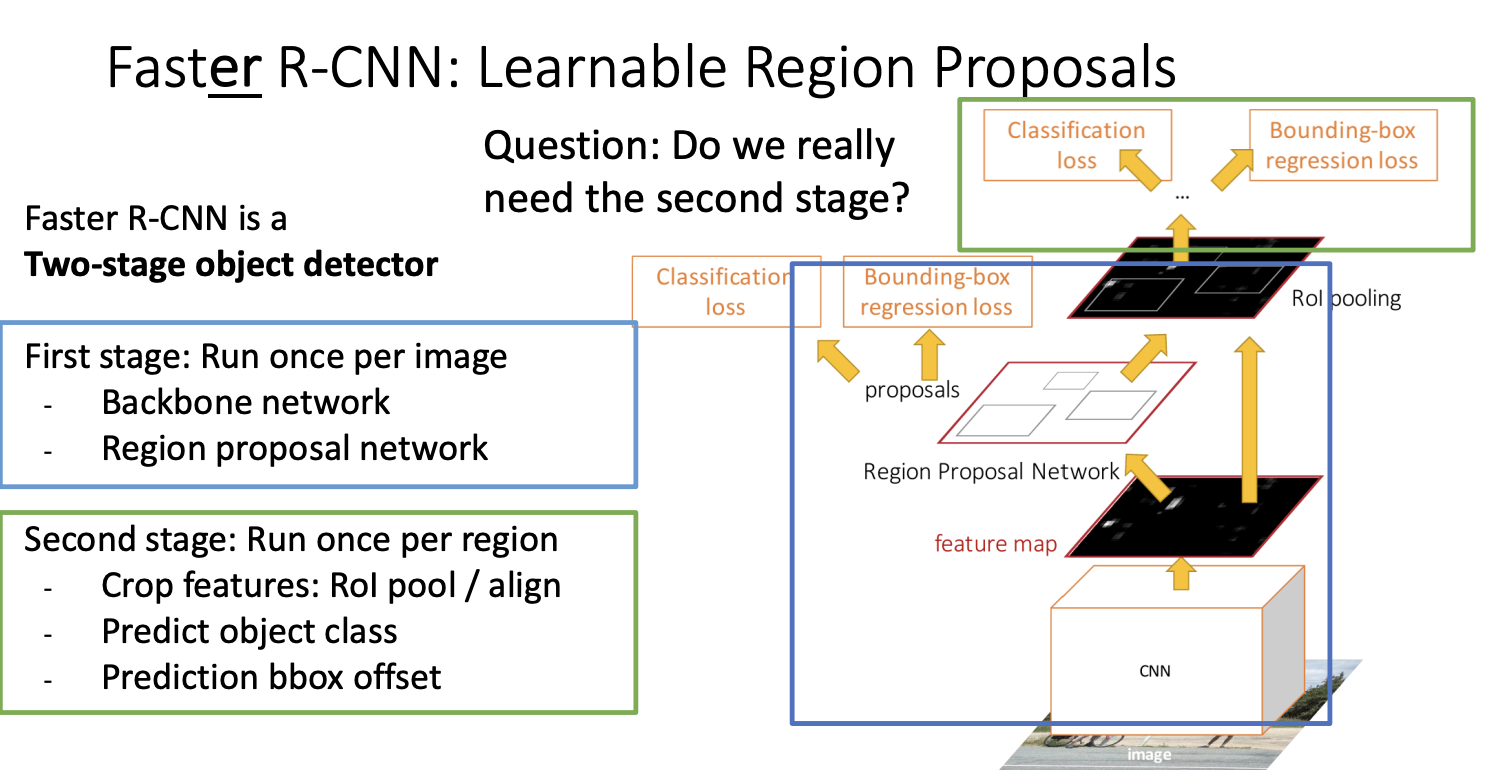
Faster R-CNN 은 Region Proposal Network(RPN) 방식을 사용하여서 기존 방식보다 조금 더 빠르게 작동한다.
Region proposal Network 방식을 설명한 사이트
https://velog.io/@suminwooo/RPNRegion-Proposal-Network-%EC% A0%95% EB% A6% AC
'Deep Learning > Computer Vision' 카테고리의 다른 글
| [Computer Vision] 컴퓨터 비전과 딥러닝 4장- 영역 분할 (0) | 2023.07.14 |
|---|---|
| [Computer Vision] 컴퓨터 비전과 딥러닝 4장- 캐니 에지 (0) | 2023.07.13 |
| [Computer Vision] 컴퓨터 비전과 딥러닝 4장- 에지 검출 (0) | 2023.07.13 |
| [Computer Vision] 컴퓨터 비전과 딥러닝 - 3장 (0) | 2023.07.06 |
| [Computer Vision] Semantic Segmentation (0) | 2023.06.28 |



