
운동하는 공대생
[Computer Vision] Semantic Segmentation 본문
1. Intro
Computer Vision에서 Object detection 다음으로 Semantic Segmentation와 Instance Segmentation 이 있다. 이것을 이미지에서 어떤 물체가 있는지를 탐지를 하는 것뿐만 아니라 이미지의 픽셀 단위로 어떤 부분이 분류한 물체가 있는지까지도 표시가 되는 장점이 있다.
2. Semantic Segmentation
2.1 Fully Convolutional
Segmentation에서 가장 흔한 방식은 Fully Convolutional 방식이다. 이것의 구조로는 CNN의 convolutional layer 들과 downsampling과 upsampling을 포함하고 있다. downsampling 은 이전 CNN의 구조에서 처럼 Pooling의 작업을 거치는 것과 같다.

2.2 Upsampling
1. Nearest Neighbor / Bed of Nails
이전 샘플에서 같은 값으로 채우는게 Nearest Neighbor 방식이고 하나의 값 이외에 나머지를 0으로 채워서 넣는 것이 Bed of Nails 방식이라고 한다.
2. Max Unpooling
Max Unpooling 방식은 이전에 Pooling layer에서 Max Pooling을 진행하면서 최고값이 있었던 위치를 기억해서 이후에 Unpooling을 진행하면서 그 위치에 값을 위치시킨다.
3. Transpose Convolution
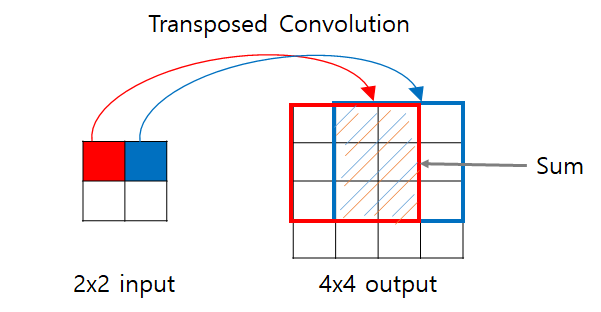
먼저 왼쪽의 그림은 기존 convolution 방식이다. 이는 이미지에서 필터를 씌우면서 이미지의 사이즈를 줄여나가는 방식이다. Transpose Convolution는 이것의 반대 방식이라고 생각하면 된다. 기존의 convolution에서 했던 것을 반대로 필터를 가지고 이미지를 upsample을 시켜준다. 이때 필터가 이미지를 upsample 시키면서 필터끼리 겹치는 빗금 부분에서는 값을 합하여 표시한다.
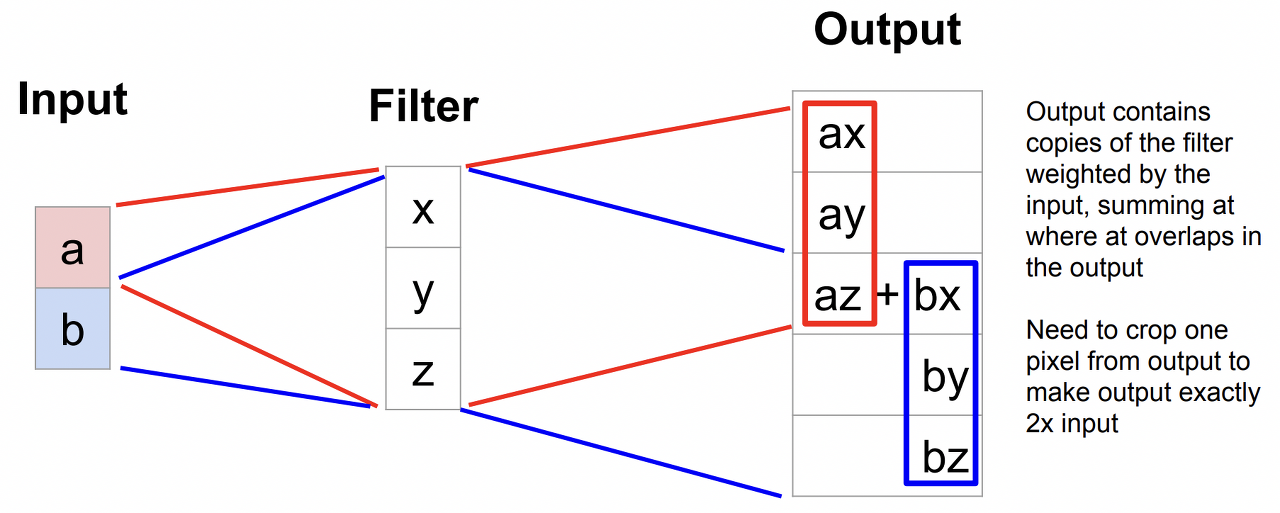
간단하게 설명하면 Input 의 데이터를 필터를 통해서 upsample을 시키고 이것을 모든 필터에 적용하고 겹치는 부분만 합하는 방식이다.
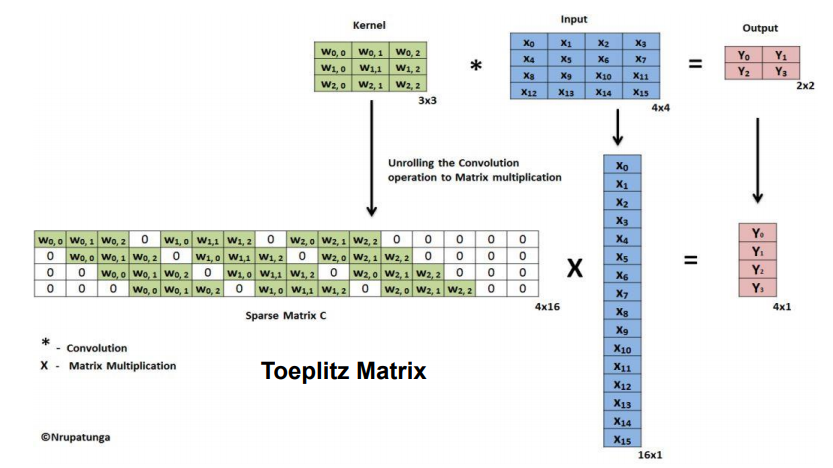
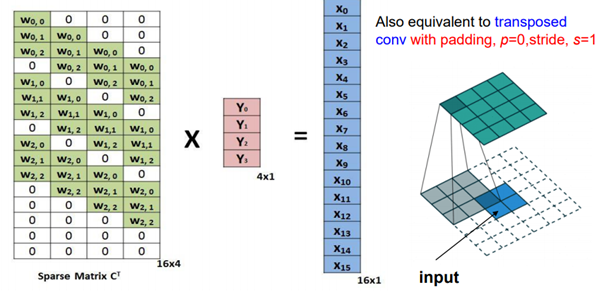
위의 두 사진은 실질적으로 동작하는 행렬곱들이 연산되는 방식이다. 왼쪽에서는 convolution 작업을 진행하는 방식이다. 필터(kernel)를 샘플링 데이터(Input)와 행렬곱 연산을 한다면 convolution작업의 결과인 output이 생성이 된다. 오른쪽 사진은 이제 다시 Transpose Convolution 작업이다. 이제 희소행렬을 Transpose를
1. 효율적인 메모리 사용: Convolution에서 필터는 입력 데이터보다 훨씬 작은 크기를 가질 수 있습니다. 만약 필터를 밀집한 행렬로 표현한다면, 대부분의 요소가 0인 메모리 공간을 차지하게 됩니다. 이는 메모리 사용을 비효율적으로 만들고, 대규모 모델이나 대용량 데이터에 대한 작업에서 문제가 될 수 있습니다. 희소 행렬을 사용하면 실제로 사용되는 요소만 저장하여 메모리를 절약할 수 있습니다.
2. 연산 효율성: Convolution은 입력 데이터와 필터 간의 행렬 곱셈으로 표현될 수 있습니다. 일반적으로 행렬 곱셈은 밀집 행렬로 계산하는 것보다 희소 행렬로 계산하는 것이 연산량이 적습니다. 희소 행렬의 특성을 이용하여 필요한 연산만 수행하면 되기 때문입니다. 따라서, 희소 행렬로 필터를 표현하면 Convolution 연산을 더 효율적으로 수행할 수 있습니다.
3. 모델 파라미터의 효율성: 딥러닝 모델에서는 필터가 모델의 학습 가능한 파라미터입니다. 희소 행렬로 필터를 표현하면 모델 파라미터의 수를 줄일 수 있습니다. 이는 모델의 복잡도를 낮추고, 과적합을 방지하며, 학습 시간을 단축시키는 데 도움을 줄 수 있습니다.
결론적으로, 희소 행렬은 필터의 크기에 비해 사용되는 요소의 수가 적은 경우에 메모리 및 계산 효율성을 높일 수 있는 방법입니다. 이러한 이유로 Transpose Convolution에서도 희소 행렬로 필터를 표현하여 역 연산을 효율적으로 수행합니다.
3. Instance Segmentation
Instance Segmentation 은 Semantic Segmentation와 다른 점은 물체의 영역만 탐지하는 게 아니라 같은 물체라도 다른 객체라는 것도 탐지가 가능하다.
3.1 Mask R-CNN
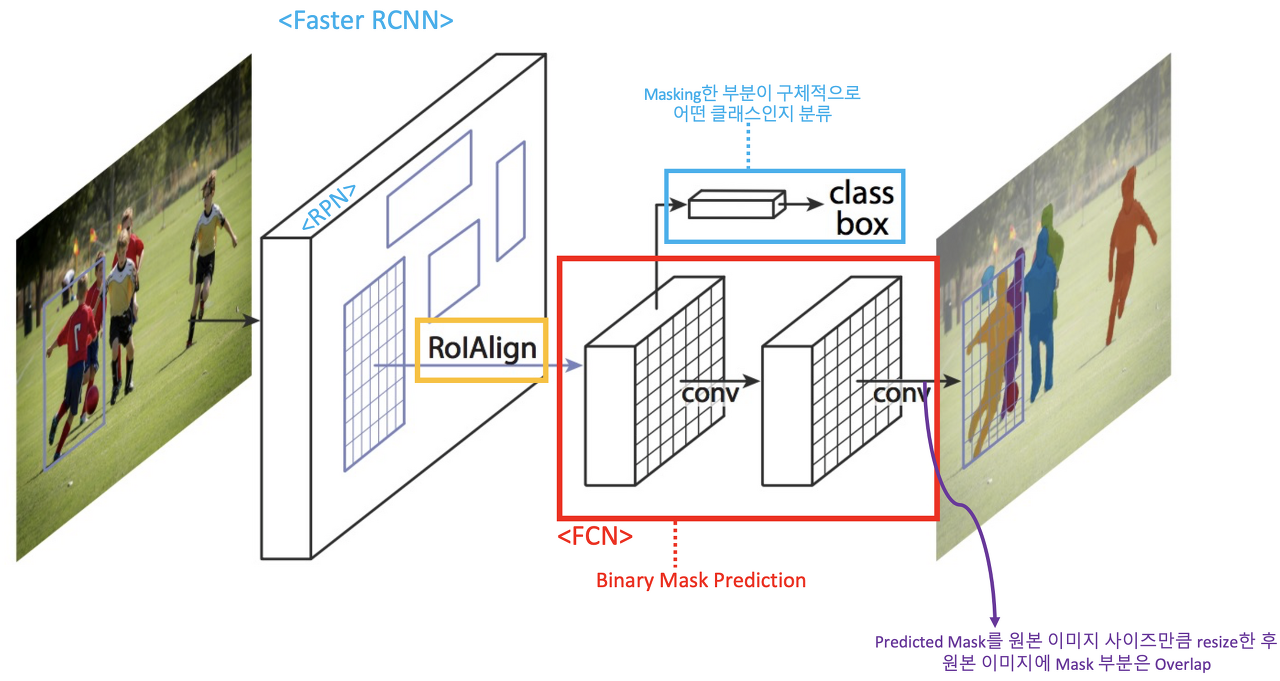
Mask R-CNN 은 Faster R-CNN 을 변형한 것으로 Faster RCNN의 프로세스를 그대로 적용하여서 feature map을 추출하고 RoIAlign 방식으로 pooling을 진행하고 이후에는 FCN (Fully convolution network)를 통해서 이미지에서 segmentation 이 가능해진다.
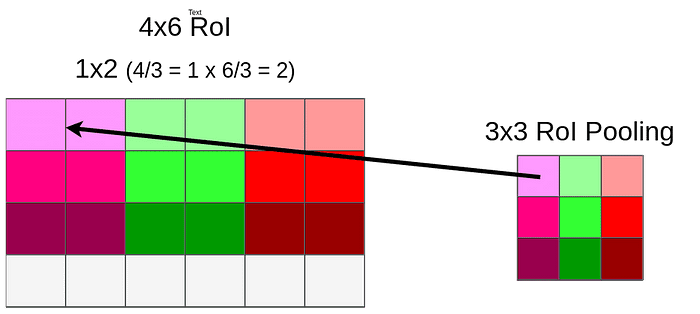
RoI 방식은 feature map 에서 pooling 할 사이즈를 기준으로 해서 크기를 나워줘서 매핑 사이즈를 설정한다. 예를 들어
4를 3으로 나누면 1.33이 남는다. 동일한 방법을 적용한 후 (소수점 이하를 내림) 1x2 벡터가 됩니다. 우리의 매핑은 다음과 같다.
'Deep Learning > Computer Vision' 카테고리의 다른 글
| [Computer Vision] 컴퓨터 비전과 딥러닝 4장- 영역 분할 (0) | 2023.07.14 |
|---|---|
| [Computer Vision] 컴퓨터 비전과 딥러닝 4장- 캐니 에지 (0) | 2023.07.13 |
| [Computer Vision] 컴퓨터 비전과 딥러닝 4장- 에지 검출 (0) | 2023.07.13 |
| [Computer Vision] 컴퓨터 비전과 딥러닝 - 3장 (0) | 2023.07.06 |
| [Computer Vision] Object Detection (0) | 2023.06.25 |



