
목록Computer Vision (3)
운동하는 공대생
 [Computer Vision] CV image overlap(cv2, PIL, image overlap,이미지 연산, 이미지 합성)
[Computer Vision] CV image overlap(cv2, PIL, image overlap,이미지 연산, 이미지 합성)
(논문을 작성하는 과정에서 개인적으로 시간이 많이 걸린 부분인데 이것을 정리하기 위해서 작성하였습니다.) 아래의 두 개의 이미지는 Imagenet data에서 가지고 온 사진이다. 여기서 두개의두 개의 이미지 데이터를 활용하여 segmentation 분야에서 두 개의 이미지를 겹치게 이미지를 편집하는 방법을 하고 싶었다. image ( 원본 이미지) mask ( segmentation의 mask) 결과 이렇게 두 개의 이미지를 겹쳐서 cv에서 모델이 얼마나 경확도를 유지하는지를 보고 싶었다. 퍼센트를 설정값으로 겹치는 정도를 나타냈으며 0~1 사이의 값을 설정하고 1이 완전히 겹치는 상황을 가정하였다. 0.7 퍼센트 0.4 퍼센트 코드 def find_contours(self, mask): ..
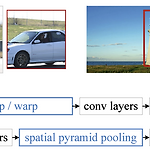 [논문] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
[논문] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
https://arxiv.org/abs/1406.4729v4 Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This requirement is "artificial" and may reduce the recognition accuracy for the images or sub-images of an arbitrary size/scale. In this work, we equip th arxiv.org 1 Intro 논문에서 제시한 문제..
 [Computer Vision] Object Detection
[Computer Vision] Object Detection
1. Intro 이전까지 공부했던 내용에서는 CNN Layer를 활용하여서 이미지를 분류하였다. 하지만 최근 들어 이미지 데이터를 활용하여 분류하는 거뿐만 아니라 다양한 분야에서는 이미지 데이터를 활용한 모델들이 사용되고 있다. 공학적인 관점에서, 컴퓨터 비전은 인간의 시각이 할 수 있는 몇 가지 일을 수행하는 자율적인 시스템을 만드는 것을 목표로 한다 (많은 경우에는 인간의 시각을 능가하기도 한다). 그리고 과학적 관점에서는 컴퓨터 비전은 이미지에서 정보를 추출하는 인공 시스템 관련 이론에 관여한다. -위키백과 Computer Vision 은 그렇게 이미지 분류뿐만 아니라 이미지에서 물체를 탐지하는 Object Detection, 물체를 분류하는 Segmentation 등등 여러 태스크에서 활용이 되고..