
목록대학원 (16)
운동하는 공대생
 [OS(운영체제)] Paging
[OS(운영체제)] Paging
1. ReviewSegmentation : 가상 메모리에서 물리적 메모리로 데이터를 메핑 할 때 데이터의 제일 앞에 있는 2개의 비트를 데이터의 종류를 구분하는 용도로 사용을 하였다.하지만 여기서의 문제는 사진에서 보여지듯이 External Fragmentation 즉 데이터를 분류하면서 데이터들 간의 작은 공간의 발생으로 메모리 낭비가 발생하는 문제가 있다. 이런 문제를 해결하기 위해서 Segmentation 에서는 데이터의 종류에 따라서 고정되지 않는 사이즈로 물리적 메모리에 적재했다면 Paging은 고정된 사이즈로 주소를 정해둔다. 이것은 나눠진 부분을 Page frame이라고 무르며 이것의 사이즈는 2의 제곱 형식으로 사이즈가 구성된다. 여기서 Page와 Frame의 블록의 크기는 같다. 2. ..
 [OS(운영체제)] Virtual memory Address translation
[OS(운영체제)] Virtual memory Address translation
1. Relocation프로세스가 물리적 메모리에 저장이 되기 위해서는 0에서 바로 시작하는 것이 아니라 메모리의 어딘가에 저장을 해야 한다. 이런 가상의 주소에서 물리적 메모리의 주소로 변환하는 과정을 relocation이라고 한다. Static Relocation소프트웨어를 기반으로 메모리에 할당을 하는 방식이다. 여기서는 메모리에 로딩할때 OS가 각각의 프로그램에 할당한다. 즉 모든 프로세스에 대한 주소를 다시 작성을 하는 것이라고 할 수 있다. 그래서 이런 방식은 하드웨어에 대한 도움이 필요하지 않지만 메모리에 직접적으로 접근하기 때문에 보안에 취약하다. 또한 메모리를 한번 할당하면 주소를 이동하는 게 힘들다. Dynamic Relocation이 방식은 하드웨어를 기반으로 작동하는 방식이다. CP..
 [OS(운영체제)] CPU 스케줄링(CPU Scheduling)
[OS(운영체제)] CPU 스케줄링(CPU Scheduling)
1. CPU Scheduling정의 : 어떤 프로세스를 다음으로 실행을 할 것인지에 대한 방식 다음에 어떤 프로세스를 실행을 해야하는지는 여러 가지 지표를 통해서 선택이 되어야 한다.Minimize trunaroung time : 작업 소요 시간Minimize response time : 최초 실행 시간 Minimize waiting time : process 대기하는 queue에서 많은 시간을 사용하지 않아야 한다.Maximize throughput : 처리율이 최대로 나와야 한다.Maximize resource utilization : 디바이스 활용을 최대화Minimize overhead : context switch를 최소화해야 한다.Maximize fairness : 같은 양의 CPU 리소스를 활..
 [대학원] 연세대학교 인공지능대학원 합격 후기
[대학원] 연세대학교 인공지능대학원 합격 후기
이번에 대학원을 준비하면서 여러 가지 정보를 찾아봤지만 생각보다 많은 정보가 없어서 정리를 시작하게 되었다.일단 나는 대학원에 대한 정보가 전혀 없어서 김박사넷에 글을 적으며 정보를 얻으려 노력했다. 하지만 거기 사람들은 뭔가.... 굉장히 세상에 불만이 많은지 좋은 대답은 전혀 해주지 않았다. 그래서 검색창에 후기들을 검색하고 유튜브를 찾아보고 그리고 주변 지인들의 경험을 기반으로 나는 대학원을 준비했다. 사실 나는 대학원을 준비하는 과정에서 전부 인턴을 시작하면서 인턴을 했던 연구실로 대학원 생활을 하는 경우가 많다. 하지만 나는 자대에서 학부 연구생을 하고 있었고 자대에서의 아쉬운 점이 많아서 타대 대학원을 준비하는 입장이라 시기상으로 많이 늦었었다. 하지만 자대에서 부족한 리소스에 대한 갈망이 존..
 [Machine Learning] 머신러닝에서 딥러닝까지 이론 정리 (1)
[Machine Learning] 머신러닝에서 딥러닝까지 이론 정리 (1)
이번 이론 정리는 혼자 머신러닝 이론에 대한 총정리를 하기 위해서 작성하였습니다. 1. Introduction Traditional Programming vs Machine Learning 기본적으로 우리가 알고 있는 프로그래밍은 프로그램을 개발하는 개발자가 프로그램에 대한 룰을 정하여 일정 데이터와 프로그램을 이용하여 결과를 도출하는 방식을 말한다. 하지만 머신러닝은 개발자가 데이터를 기반으로 데이터에 대한 패턴을 학습하여서 새로운 데이터가 입력되었을 때 결과를 도출하는 방식으로 이루어진다. 이런 머신러닝에서 데이터를 설명하는 학습 방식에는 두가지가 존재한다. Supervised Learning vs Unsupervised Learning Supervised Learning 은 한국어로 지도학습 이라고..
 [Clustering]Maximum Likelihood Estimation-최대우도법
[Clustering]Maximum Likelihood Estimation-최대우도법
1. What is Maximum Likelihood Estimation(MLE) MLE 의 정의는 확률밀도함수 P(x|θ) 에서 관측되는 표본 데이터 x 를 통해서 θ 를 추정하는 방식이다. 5개의 데이터가 있다고 가정을 해보자. x={1,4,5,6,9} 이중에서 데이터의 분포가 어떤 곡선이 더 데이터에 맞는 분포인지를 수학적으로 풀이한게 MLE 방식이라고 이야기한다. 2. Likelihood function 그렇다면 각 데이터의 분포를 측정하기 위해서 후보 분포들 중에서 데이터와 가장 맞는 분포인지를 수치적으로 환산하는 방식이 있어야 하는데 이것을 Likelihood funcion을 통해서 가능도를 수치화 한다. 식을 해석하자면 k 가 1 에서부터 n 까지 있다고 가정하면 이것의 데이터의 확률 밀도값..
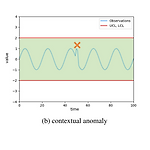 [논문]Deep Learning for Anomaly Detection inTime-Series Data: Review, Analysis,and Guidelines
[논문]Deep Learning for Anomaly Detection inTime-Series Data: Review, Analysis,and Guidelines
0. Intro 이 논문에서는 먼저 Time-series 데이터에서 Anomaly Detection을 하는 과제를 수행할 때 기본적인 데이터에 대한 특징이나 모델이 고려해야 하는 사항들에 대한 가이드라인을 제시를 해주었다. https://ieeexplore.ieee.org/document/9523565 Deep Learning for Anomaly Detection in Time-Series Data: Review, Analysis, and Guidelines As industries become automated and connectivity technologies advance, a wide range of systems continues to generate massive amounts of dat..
 [Computer Vision] 컴퓨터 비전과 딥러닝 5장- 매칭
[Computer Vision] 컴퓨터 비전과 딥러닝 5장- 매칭
지역 특징에서 매칭은 이전까지 영상에서 찾았던 특징점들을 서로 다른 영상에서 짝지어 주는 방식에 대하여 이야기를 하겠다. 1. 매칭 전략 각각 다른 영상에서 추출한 기술자들의 집합을 A, B 가 있다고 가정하면 여기서 가장 간단한 방법은 각 집합들의 모든 요소들의 거리를 계산하여 일정 임계치보다 작으면 매칭을 시키는 방식이 있다. 하지만 이런 방식에서는 매칭된 쌍과 같은 곳인데 매칭에 실패하는 경우, 같은 곳이 아닌데 매칭되는 경우의 문제가 자주 발생한다. 보통 거리 계산을 할 때는 유클리디안 거리를 사용한다. 이렇게 추출한 기술자들을 서로 다른 영상에서 매칭을 시키는 작업은 3가지 정도가 있다. 1. 두 기술자의 거리가 임곗값보다 작으면 매칭 보통 가장 기초적인 방식으로 임곗값보다 거리가 작으면 매칭되..