
운동하는 공대생
[Computer Vision] 컴퓨터 비전과 딥러닝 5장- 매칭 본문
지역 특징에서 매칭은 이전까지 영상에서 찾았던 특징점들을 서로 다른 영상에서 짝지어 주는 방식에 대하여 이야기를 하겠다.
1. 매칭 전략
각각 다른 영상에서 추출한 기술자들의 집합을 A, B 가 있다고 가정하면 여기서 가장 간단한 방법은 각 집합들의 모든 요소들의 거리를 계산하여 일정 임계치보다 작으면 매칭을 시키는 방식이 있다. 하지만 이런 방식에서는 매칭된 쌍과 같은 곳인데 매칭에 실패하는 경우, 같은 곳이 아닌데 매칭되는 경우의 문제가 자주 발생한다. 보통 거리 계산을 할 때는 유클리디안 거리를 사용한다.

이렇게 추출한 기술자들을 서로 다른 영상에서 매칭을 시키는 작업은 3가지 정도가 있다.
1. 두 기술자의 거리가 임곗값보다 작으면 매칭
보통 가장 기초적인 방식으로 임곗값보다 거리가 작으면 매칭되는 방식이다.
2. 초근접 이웃(nearest neighbor)
기술자 집합 A, B 에서 A 집합의 요소 중 한 개의 a 가 B 집합 안에서 가장 거리가 가까운 b 요소를 찾고 이것이 위 방식처럼 임곗값의 조건을 만족하면 매칭한다.
3. 초근접 이웃 거리 비율
2번째 방식 처럼 A와 B의 요소 중 가장 가까운 지점 bj를 계산하고 두 번째로 가까운 bk를 계산하여 이것의 비율을 계산하고 임곗값과 비교하여 매칭한다.
2. 매칭 성능 측정
2.1 정밀도와 재현율
-혼동 행렬
혼동 행렬은 인공지능 분야에서 모델이나 알고리즘에 대한 정답의 정확도를 측정하기 위해서 실제 정답과 모델의 예측값의 경수의 수를 모두 표시한 행렬이다.
- True Positive(TP) : 실제 True인 정답을 True라고 예측
- False Positive(FP) : 실제 False인 정답을 True라고 예측
- False Negative(FN) : 실제 True인 정답을 False라고 예측
- True Negative(TN) : 실제 False인 정답을 False라고 예측
이렇게 총 4가지 경우로 나뉘어지며 TP, FN이 예측을 잘했다고 판단하는 게 가능하다.
-정밀도, 재현율
정밀도(precision) : 매칭 알고리즘이 긍정, 즉 매칭 쌍으로 예측한 개수 중에 진짜 쌍인 비율
재현율(recal) : 진짜 쌍 중에 알고리즘이 찾아낸 쌍의 비율
F1 : 정밀도와 재현율을 둘 다 고려

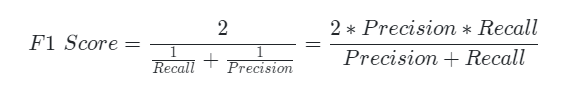
- ROC 곡선과 AUC
True positive rate(TPR) : TP/(TP+FN)
False positive rate(FPR) : FP/(TN+FP)

그림에서 보듯이 가장 좋은 성능을 보이는 상황은 A=0.95 인 상황으로 부정으로 예측을 해야 하는 상황에서 긍적으로 예측한 잘못된 상황 FPR 상황이 적으면서 TPR 상황의 비율이 큰 상황이 성능이 가장 좋다 그리고 곡선의 아래의 면적은 AUC(area under curve)라고 이야기를 하며 종종 성능 측정 지표로 사용된다.
3. 빠른 매칭
3.1 kd 트리
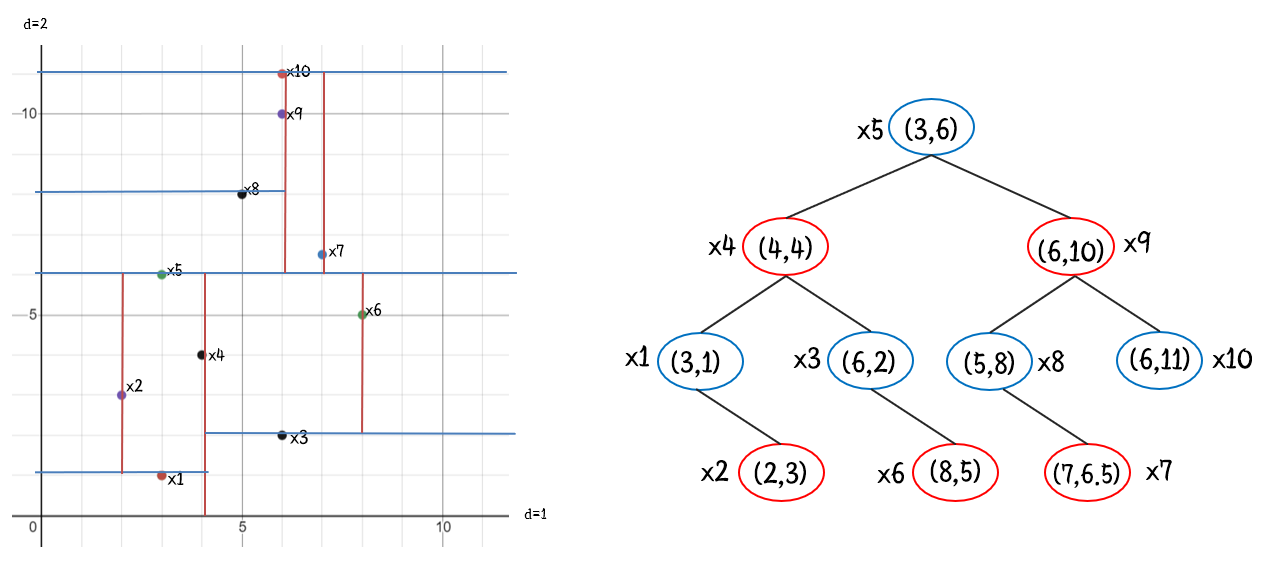
각각 기줄자들이 있는 집합을 X라고 하고 각각의 요소를 예시로 들면 이렇게 표시가 된다.
X = {x1:(3,1), x3:(6,2), x2:(2,3), x4:(4,4), x6:(8,5), x5:(3,6), x7:(7, 6.5), x8:(5,8), x9:(6,10), x10:(6,11)}이 됩니다.
여기서 이제 1번째축(요소의 첫 번째 값), 2번째 축(요소의 두 번째 값)을 기준으로 분산이 큰 축을 기준으로 왼쪽 오늘 쪽 집합을 left, right 각각 나눈다.
X_left = {x1:(3,1), x3:(6,2), x2:(2,3), x4:(4,4), x6:(8,5)}, X_right = {x7:(7, 6.5), x8:(5,8), x9:(6,10), x10:(6,11)}가 됩니다.
그렇게 트리의 루트 노드를 지정을 했다면 각각 왼쪽 오른쪽의 집합을 다시 이전에 했던 방식처럼 한개의 축을 기준으로 왼쪽 오른쪽을 분할한다. 이렇게 재귀적으로 트리를 생성하여서 데이터 상으로는 트리가 만들어지고 공간상에서는 공간을 분할하는 축이 생성이 된다.
-탐색
이제 kd 트리에서 초근접 이웃을 찾는 과정을 설명하겠다.
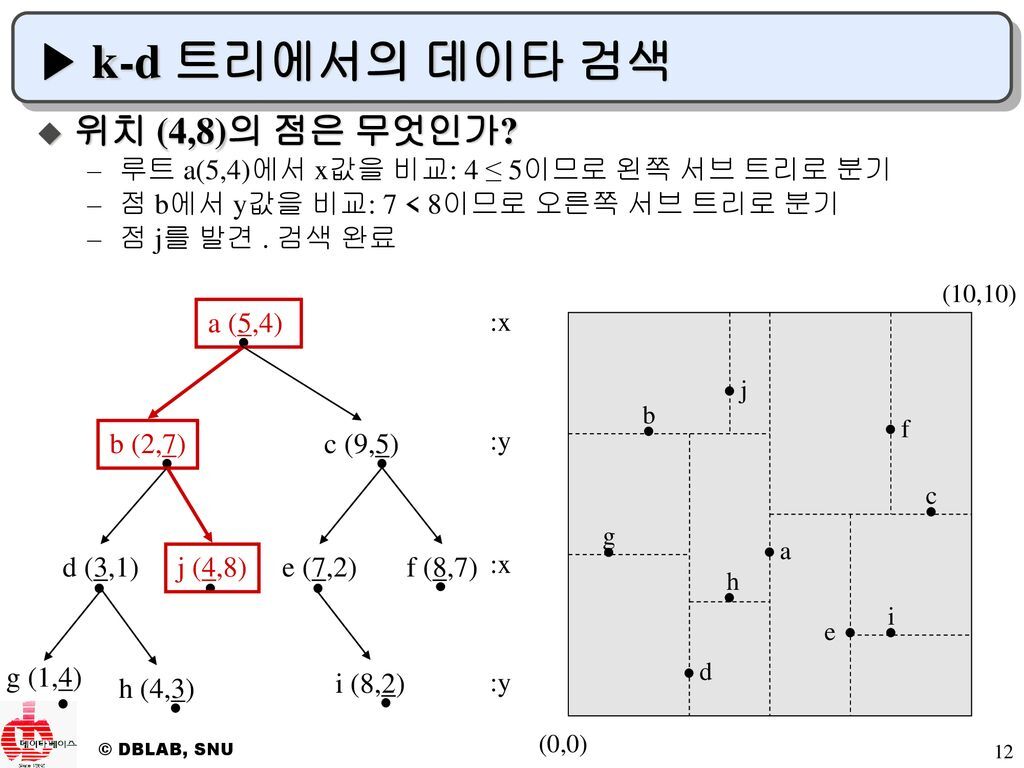
먼저 그림에서 처럼 트리가 구성이 되어 있다고 한다고 가정하면 4,8 값이 들어가면 먼저 루트 노드 a의 축이 첫 번째 요소가 축임으로 5와 비교를 해서 더 작음으로 왼쪽으로 이동한다. 오른쪽 공간에서는 a의 왼쪽의 값들 즉 축의 왼쪽의 값들만 비교를 한다 그 이후에는 b로 넘어가면 축은 7인 세로축임으로 기교하면 입력값 8 이 더 크니 트리에서는 오른쪽 공간상으로는 b 가로축의 위의 값만 탐색하고 결국에는 이렇게 반복하면 j 가 최종적으로 탐색된다.
하지만 한계는 명확한데 이웃 칸에 더 가까운 점이 존재할 가능성이 있다. 트리 구조에서 탐색을 진행함으로 분명 더 다까운 지점이 존재하는 게 가능하다. 그래서 추가로 경로를 역추적하는 과정이 필요한데 이는 시간을 더 오래 끈다. 그래서 이를 해결하기 위해서 최근접 이웃 대신 근사 최근접 이웃을 찾는다.
이후에는 해싱, FLANN, FAISS등등 다양한 방법이 제시되었다.
'Deep Learning > Computer Vision' 카테고리의 다른 글
| [Computer Vision] CV image overlap(cv2, PIL, image overlap,이미지 연산, 이미지 합성) (0) | 2024.07.16 |
|---|---|
| [Computer Vision] 컴퓨터 비전과 딥러닝 5장- 호모그래피 추정 (0) | 2023.07.28 |
| [Computer Vision] 컴퓨터 비전과 딥러닝 4장- 대화식 분할, 영역 특징 (0) | 2023.07.14 |
| [Computer Vision] 컴퓨터 비전과 딥러닝 4장- 영역 분할 (0) | 2023.07.14 |
| [Computer Vision] 컴퓨터 비전과 딥러닝 4장- 캐니 에지 (0) | 2023.07.13 |



