
운동하는 공대생
[논문]Deep Learning for Anomaly Detection inTime-Series Data: Review, Analysis,and Guidelines 본문
[논문]Deep Learning for Anomaly Detection inTime-Series Data: Review, Analysis,and Guidelines
운동하는 공대생 2023. 7. 24. 16:450. Intro
이 논문에서는 먼저 Time-series 데이터에서 Anomaly Detection을 하는 과제를 수행할 때 기본적인 데이터에 대한 특징이나 모델이 고려해야 하는 사항들에 대한 가이드라인을 제시를 해주었다.
https://ieeexplore.ieee.org/document/9523565
Deep Learning for Anomaly Detection in Time-Series Data: Review, Analysis, and Guidelines
As industries become automated and connectivity technologies advance, a wide range of systems continues to generate massive amounts of data. Many approaches have been proposed to extract principal indicators from the vast sea of data to represent the entir
ieeexplore.ieee.org
1. Back ground
1.1 anomalies in time-series data

- point anomaly
point anomaly 는 데이터가 특정 한 지점에서 범위를 벗어나는 상황에 대한 오류이다. Time-series 데이터의 특성상 센서에 대한 오류나 일시적인 노이즈로 범위를 벗어나는 경우도 발생하기도 한다. 여기서 범위에 대한 상위, 하위값을 지정을 하면 Upper control limits, Lower control limits 각각 UCL, LCL을 지정을 해준다.
- contextual anomaly
point anomaly 케이스와 비슷하게 일반적으로 나오는 상황이아닌 한 특정 시간에서 이상치가 발생하는 경우이다. 하지만 임곗값의 범위를 벗어나지 않으며 데이터의 변화가 예상되는 패턴에서 벗어나는 경우에 해당한다. 이는 이런 이유로 탐지하기 어렵다.
-collective anomaly
이전과는 다르게 특정 시간에 갑자기 발생하는게 아니라 이상한 이상치가 지속적으로 지속되는 상황을 말한다. 한 번에 탐지하는 게 어렵고 일정 시간이 지나야 이상치를 탐지하는 게 가능하다.
-other anomaly types
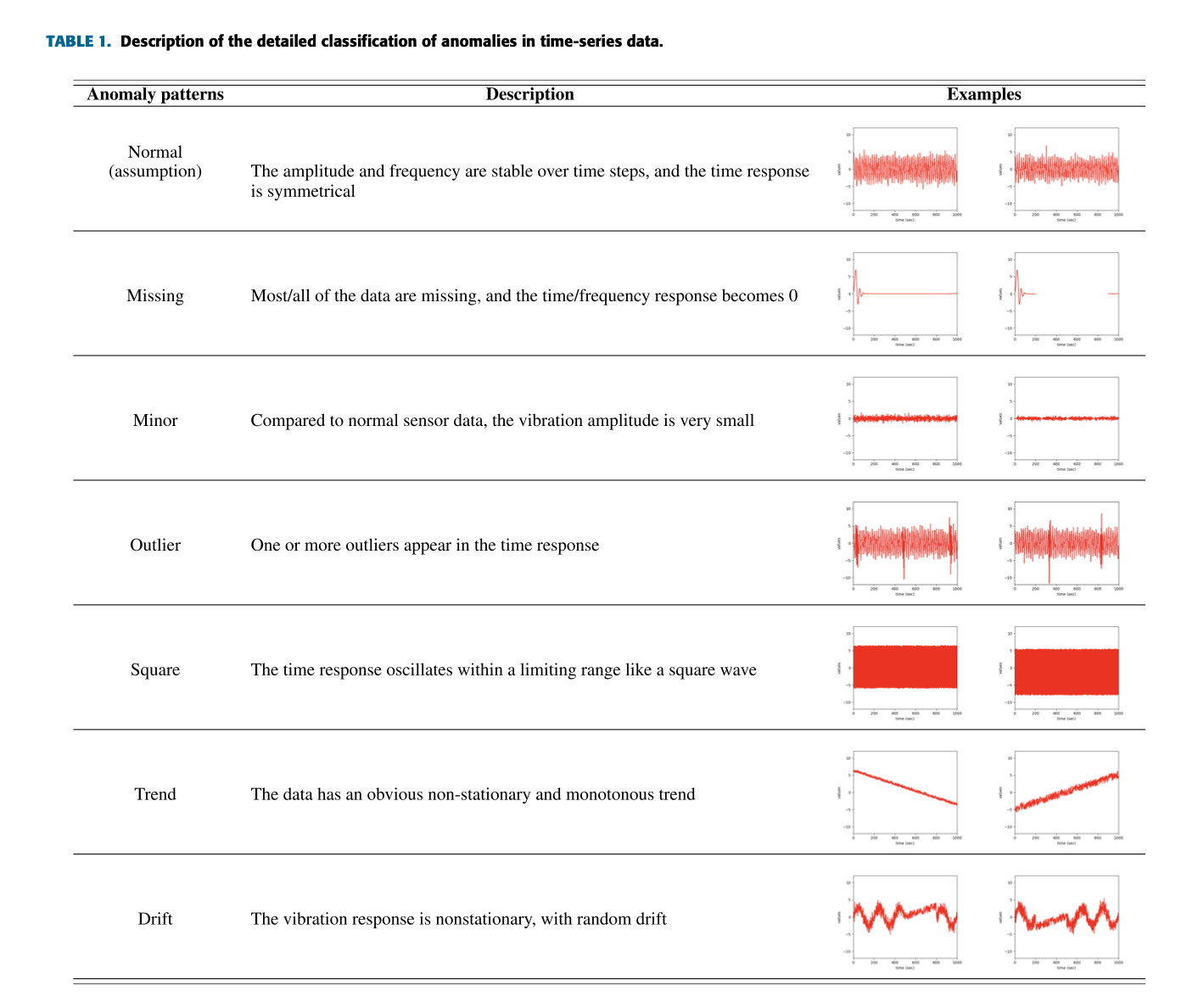
이전 방식와 조금 다른 데이터들의 패턴이다.
1.2 properties of time-series data
- temporality
time series 데이터는 이전의 데이터들과 연관이 되어있으면 일정한 주기마다 데이터가 관측된다.
-dimensionality
데이터에 차수가 존재하며 차수에 따라서 계산 연산에 대한 코스트가 달라진다.
univariate: 시간과 데이터만을 고려만 하여 단순한 데이터 형식이다.
multivariate: 다 차원에서는 차원간의 연관성과 관측값 간의 관계를 모두 고려해야 한다.
-nonstationarity
seasonality: 계절성은 시간에 관련된 데이터 임으로 시간에 흐름에 따라 변화하는 데이터들이 존재할 것이다. 이것을 이상치가 아닌 데이터로 판단해야 한다.
concept drift: 이상치가 아닌 일시적으로 비정상적으로 변화는 상황.
change points: 산업 분야에서 처럼 새로운 시작을 진행하거나 다른 세팅값으로 프로세스를 시작할 때 달라지는 부분에 대한 문제이다.
-noise
신호처리 과정에서 발생하는 그런 노이즈에 대한 문제는 항상 고려를 해야 한다.
2.Classical Approaches
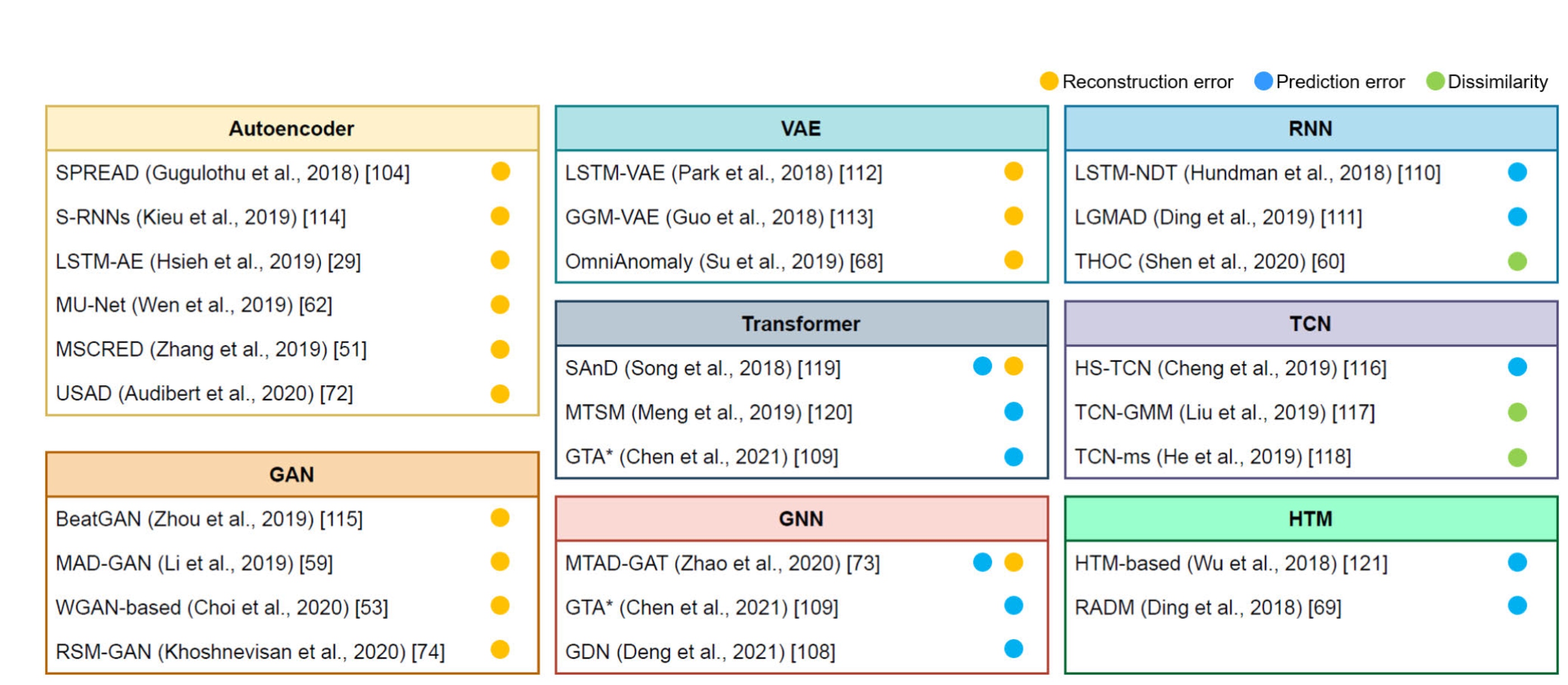
위의 사진처럼 기존의 모델이 어떻게 time-series 데이터를 처리하는 방식에 따라 분류를 해두었다.
2.1 Time/Frequency domain analysis
단순하게 시간과 측정값의 임곗값을 통해서 분석하는 방식이다. 여기서 자주 사용하는 방식은 Fourier analysis 방식으로 복잡한 주기를 가진 time series 데이터를 단순화하여 주기를 만들어주는 방식이다. 그렇게 변환해서 Timee domain의 데이터를 Frequency domain으로 변경한다.
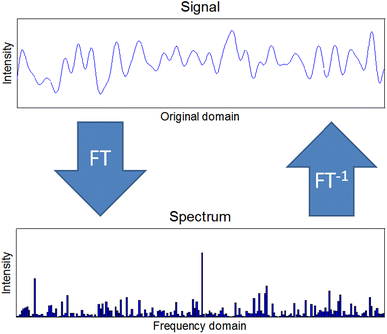
2.2 Statistical model
단순히 수학적으로 데이터를 분석하는 방식으로 데이터에 대한 평균치나 분산, 표준편차 등등을 활용하여 분석한다.
2.3 Distance-Based model
거리를 기반으로 계산하는 방식으로 서로 다른 시간에서 데이터 간의 거리를 측정한다. 여기서 가장 유명한 방식으로는 Dynamic time warping(DTW) 방식으로 Euclidean 방식과 다르게 주기가 조금 달라도 계산이 가능하다.

2.4 Predictive model
LSTM이나 ARIMA처럼 이전의 데이터를 기반으로 현재 상황을 예측하는 방식이다.
2.5 Clustering model
각각의 시점마나 군집화를 통해서 이상치를 탐지하는 방식
3. challenge
- Lack of labels
이전 방식들과는 다르게 정확한 답이 있는 supervised 방식과 다르며 각 상황마나 판단되는 이상치에 대한 상황이 다를 수 있다.
- Complexity of data
현재는 한 차원에서만 데이터와 시간상의 관계를 보는 게 아니라 시간과 여러 차원에 대한 관계까지도 고려를 해야 해서 더욱 분석에 어려움이 있다.
4. Guidelines for practitioners
Time series 데이터를 활용한 모델들을 사용하여 적용을 한다고 한다면 몇 가지 고려를 해야 하는 점들이 있다.
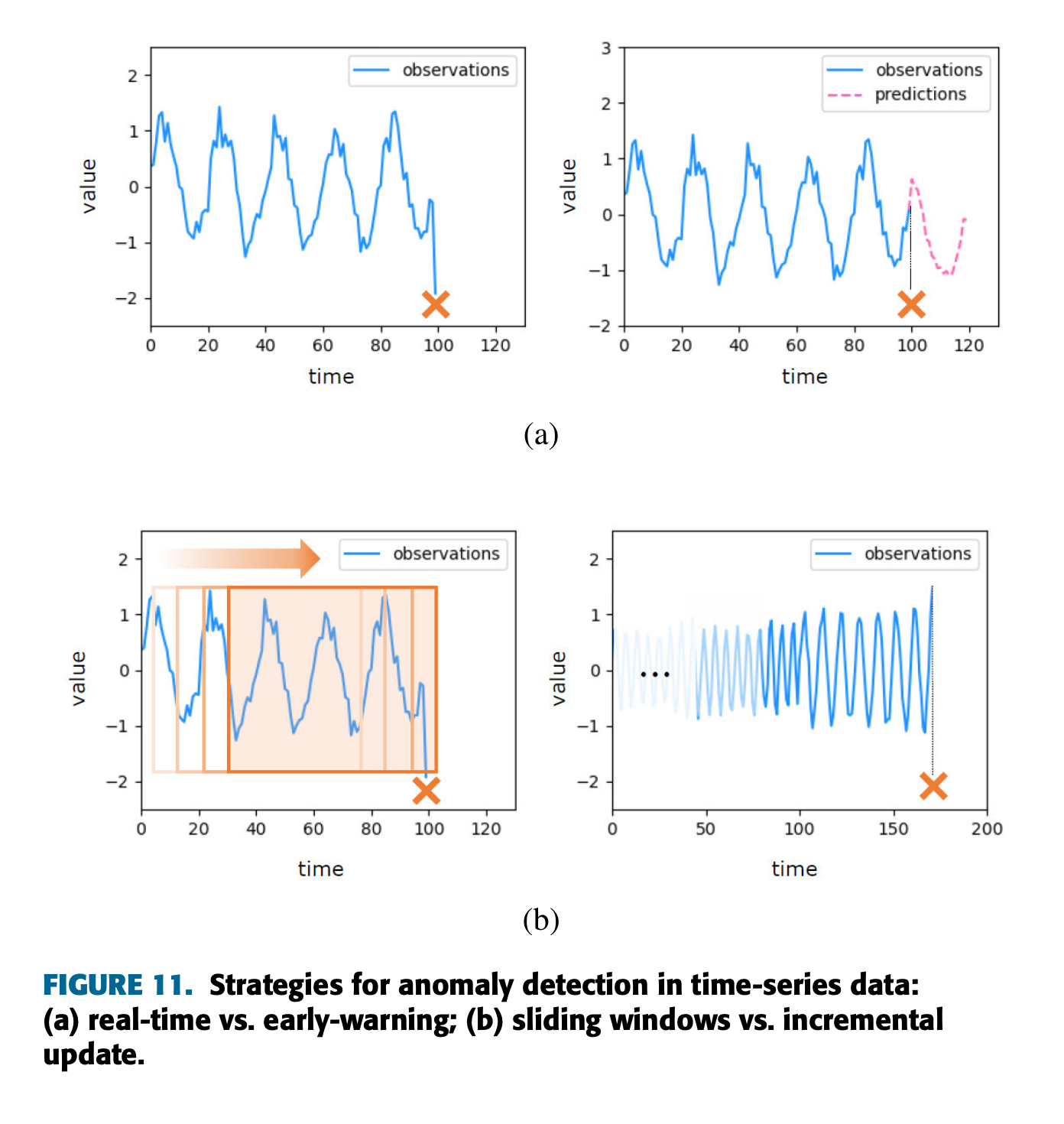
4.1 Real-time vs Early-warning
- Real-time
실시간으로 이상치를 탐지해야 하는 상황에서는 논문에서 보통 GRU, CNN 기반의 모델들을 활용한다고 이야기를 했다. 실시간으로 예측을 진행하는 모델들을 추론하는 시간이 실시간 예측 성능을 좌우하는 큰 문제임으로 추론시간이 짧은 모델들을 활용해야 한다.
- Early Warning
예측을 기반으로 하는 이 모델은 보통 LSTM이나 HTM 모델을 주로 사용하며 여기서의 가장 큰 문제는 이상치를 탐사하지 못하거나 잘못 탐지를 하는 것이다. 여기서는 임곗값의 설정에 의하여 오류가 자주 발생하는데 임곗값이 너무 낮으면 잘못된 탐지 즉 정상인데 이상치라고 판단하는 케이스가 늘어날 것이고 임곗값을 너무 높게 잡으면 탐지를 하지 못하는 경우가 생긴다.



