
운동하는 공대생
[Deep Learning] CNN-Convolutional Neural Networks 본문
1. Features

각각 생성한 패턴의 이미지는 2차원의 작은 이미지 형태로 표시하며 패턴을 각각 이미지에 위치시켜서 이미지 패턴이 얼마나 겹치는지를 수치적으로 정의가 가능하다.
2. Convolution
각각의 생성한 패턴을 이미지에 매칭을 시켜서 수치적으로 환산을 하는 방식을 convolution 방식이라고 한다. 이 방식은 각각 생성한 패턴을 이미지에 대조해서 각 자릿수를 곱하여 총합의 평균으로 그 이미지와 패턴의 매칭되는 정도를 수치화한다. 이때 패턴과 이미지가 같은지 다른지를 각각의 픽셀 단위로 계산이 이루어지며 만약 같은 부분이라면 1 ( 1 * 1 =1 or -1 * -1 =1 )다르면 -1 ( 1 * -1 = -1 or -1 * 1 =-1)이 된다.
이렇게 이미지에 패턴을 모두 오버랩을 해서 convolution을 해주면 이미지에서 패턴이 수치 적으러 어떤 위치에 겹치는지를 환산하는 게 가능하다. 이렇게 나온 결과의 이미지를 Activation map(활성화 지도)이라고 표현한다.
이런 Activation map 은 각각의 생성된 패턴(filter) 마다 생성이 된다.
Convolution Process
- Overlap the convolution filter and the image patch
- Multiply each image pixel by the corresponding filter coefficient
- Add them up
- Divide by the total number of pixels in the feature.(optional)
3. Convolution Layer
Channel
이미지 픽셀 하나하나는 실수입니다. 컬러 사진은 천연색을 표현하기 위해서, 각 픽셀을 RGB 3개의 실수로 표현한 3차원 데이터입니다.(<그림 2> 참조) 컬러 이미지는 3개의 채널로 구성됩니다. 반면에 흑백 명암만을 표현하는 흑백 사진은 2차원 데이터로 1개 채널로 구성됩니다. 높이가 39 픽셀이고 폭이 31 픽셀인 컬러 사진 데이터의 shape은 (39, 31, 3)**3**으로 표현합니다. 반면에 높이가 39픽셀이고 폭이 31픽셀인 흑백 사진 데이터의 shape은 (39, 31, 1)입니다.

Convolution Layer에 유입되는 입력 데이터에는 한 개 이상의 필터가 적용됩니다. 1개 필터는 Feature Map의 채널이 됩니다. Convolution Layer에 n개의 필터가 적용된다면 출력 데이터는 n개의 채널을 갖게 됩니다.
Convolution Layer
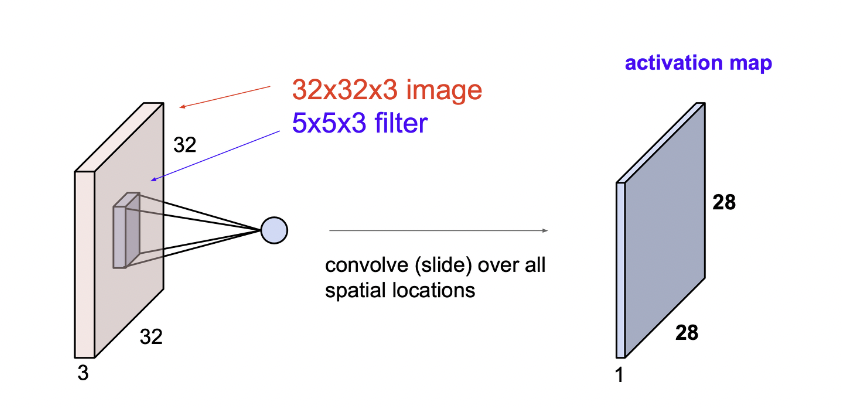
이렇게 위에서 설명한 32*32*3(depth or chennel) 의 이미지를 각각 패턴의 filter을 convolution 작업을 해주면 각 패턴의 종류마다 하나의 activation map 이 만들어진다.
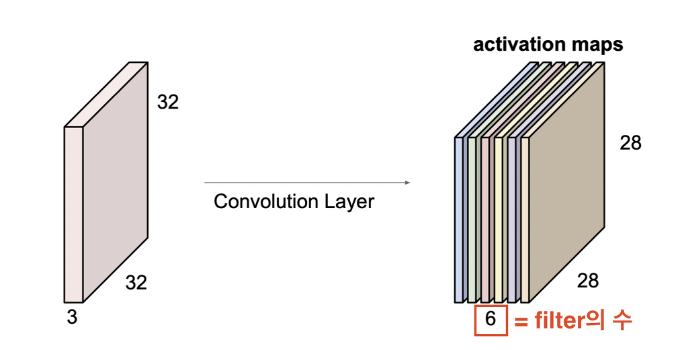
가령 filter의 수가 6개라면 총 6개의 activation map이 생성된다.
4. Pooling Layer
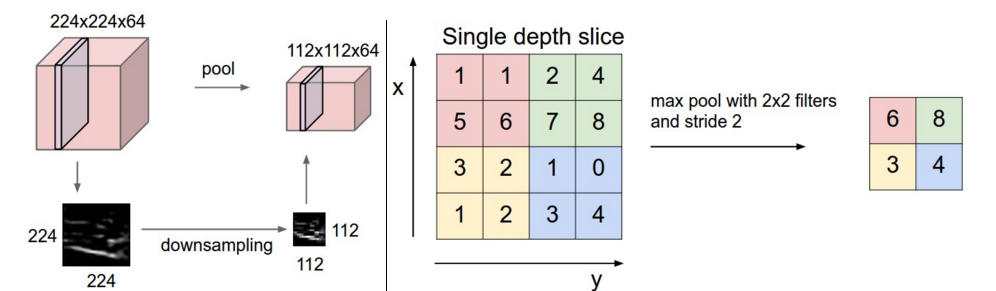
CNN 에서 pooling layer는 네트워크의 파라미터 개수나 연산량을 줄이기 위해 input에서 spatial 하게 downsampling을 진행해 사이즈를 줄이는 역할을 합니다. 일반적으로 CNN에서는 Convolution layer 다음에 들어갑니다. 본문에서 소개하는 max pooling 외에도 average pooling, L2-norm pooling 등 다양한 pooling 방법이 있습니다. Pooling(downsampling)이 필요한 이유는, featuremap의 weight parameter 갯수를 줄이기 위함입니다. pooling layer가 없다면, 너무 많은 weight parameter가 생기고, 심각한 overfitting을 유도할 수도 있고, 많은 연산을 필요로 하게 됩니다.
- max pooling layer ⇒ pooling 하려는 부분의 가장 큰 값(대부분 이 방식 사용)
- min pooling layer = pooling 하려는 부분의 가장 작은값(보통 정보 전달이 어렵다, relu 하면 0으로 변환되니까)
- average pooling layer ⇒ pooling 하려는 부분의 평균값
5. ReLU Layer
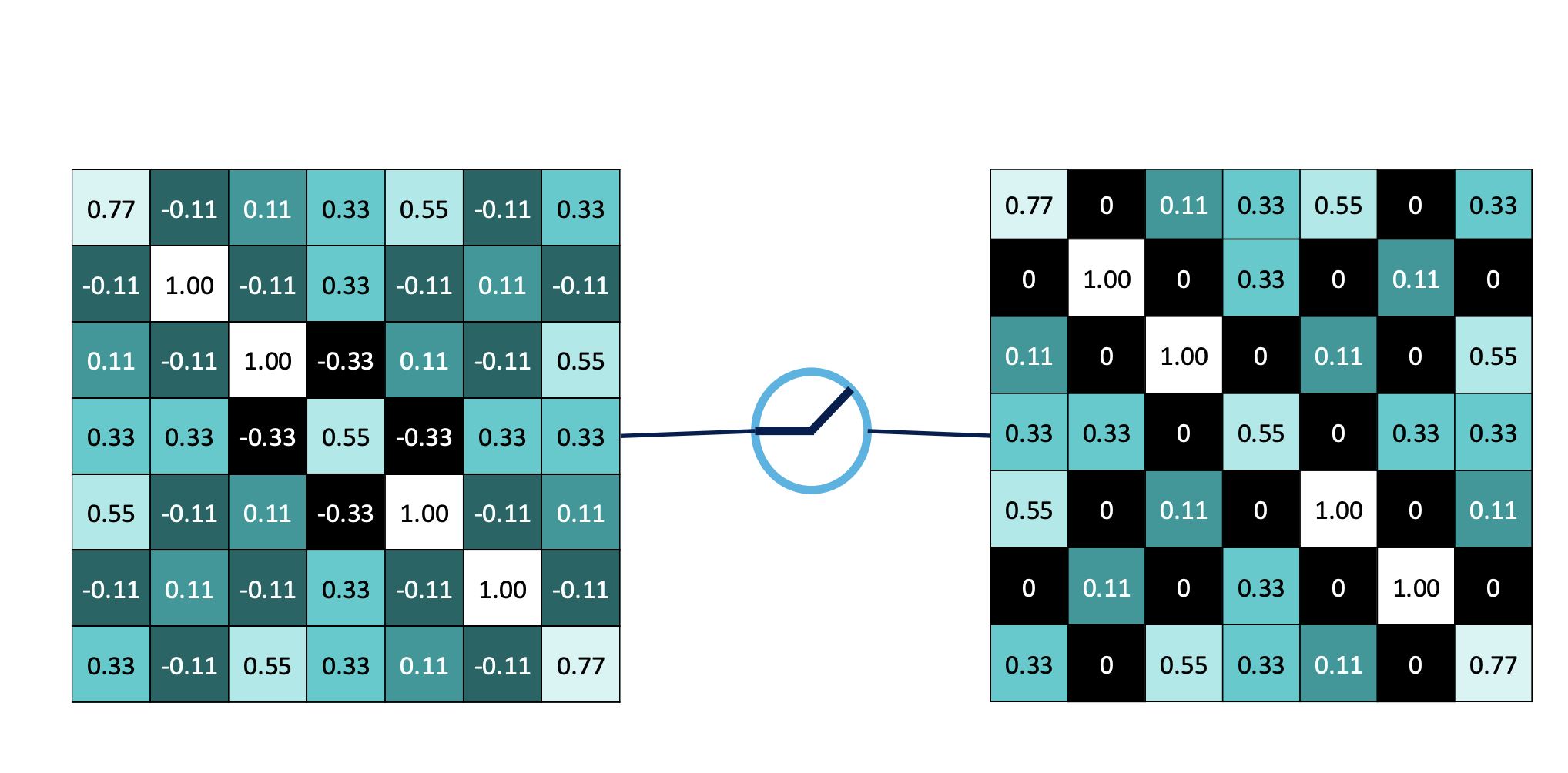
convolution 과정을 통해 선형과정에서 relu 의 activation function을 적용하여 비선형적 특성을 만들어 줌으로써 모델 학습의 성능과 속도를 늘렸다.
6. Fully Connected Layer
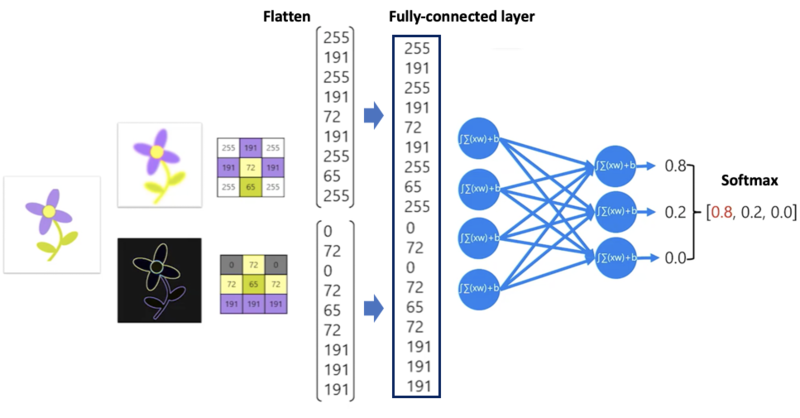
- flatten : 각 레이어를 1차원 벡터로 변환
- fully-conneced layer : 1차원 벡터로 변환된 레이어를 하나의 벡터로 연결 (각 층의 노드들은 하나로 연결)
최종적으로 분류를 결정하는 layer로 pooling 된 이미지의 데이터를 가지고 벡터화(flatten)을 시켜주고 결괏값을 softmax 방식으로 표현을 해서 분류를 해주는 방식이다.
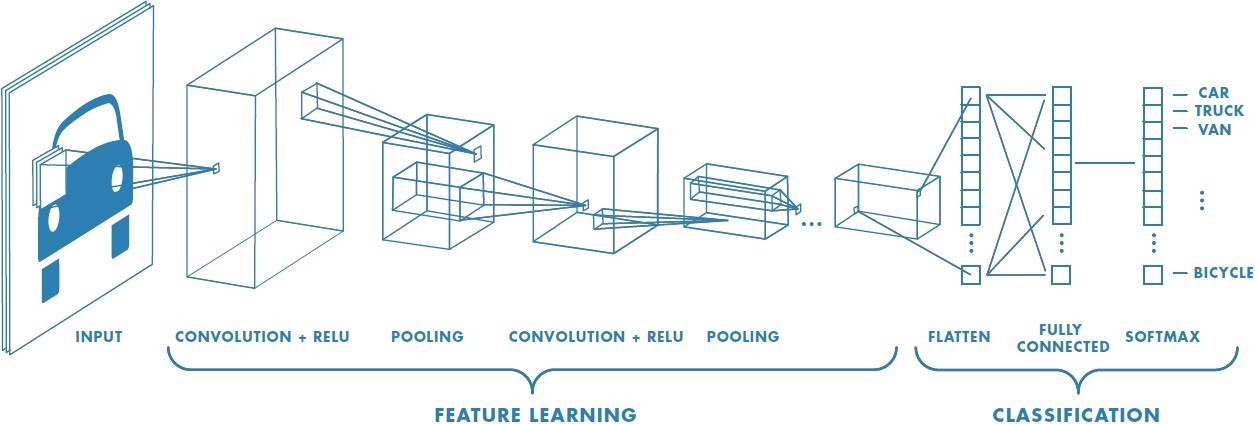
CNN Layers
7. Error Correction
최종적으로 도출된 softmax 확률값을 통해서 실제 값이랑 비교하여 binary cross entropy loss 방식이나 mse loss 방식을 통해서 loss 값을 계산하고 back propagation을 진행하여 fully connected layer의 가중치 파라미터를 수정한다. 하지만 pooling과 relu에는 가중치가 없어서 조정을 할 수 없지만 convolution layer의 가중치 조절은 가능하다.
8. Hyperparameters
- Convolution
- Number of filters
- Size of filters
- Pooling
- Window size
- Window stride
- Fully Connected
- Number of layers
- Number of neurons
'Deep Learning' 카테고리의 다른 글
| [Deep Learning]Quantization (양자화) (1) | 2025.01.02 |
|---|---|
| [Deep Learning] GCN - Graph Convolution Network (0) | 2023.07.04 |
| [Deep Learning] 다층 퍼셉트론 이론과 역전파 (0) | 2022.12.15 |
| Deep Learning(딥러닝) (0) | 2022.11.17 |
| GAN(Generative Adversarial Networks)(3/3) (0) | 2022.10.21 |



