
운동하는 공대생
[NLP] 워드 임베딩(Word Embedding 2/2)- 예측 기반 벡터(Word Embedding, Word2Vec) 본문
[NLP] 워드 임베딩(Word Embedding 2/2)- 예측 기반 벡터(Word Embedding, Word2Vec)
운동하는 공대생 2022. 12. 28. 13:49이전 까지는 문장에서 단어의 빈도를 바탕으로 하는 NLP 방법을 알아보았다. 이 방식의 큰 문제는 단어의 빈도를 바탕으로 처리를 해서 문서의 특징을 파악하는 건 가능하지만 각 단어 간의 유사성이나 의미를 파악하기는 어렵다. 예를 들어서 뜻이 다른 같은 단어가 여러 개 나오는 문장에서 이전 방식을 사용하면 의미를 파악하기보다는 문장의 특징을 파악하는 건 가능하지만 그 단어가 다르다는 의미를 파악하기는 어렵다 가령 '날아다니는 파리'와 '프랑스의 수도인 파리' 같은 예시이다.
워드 임베딩
예측을 기반으로 하는 벡터 임베딩 방식을 이용하기 이전에 단어를 수치적으로 표현하는 방식인 워드 임베딩 방식을 꼭 알아햐 한다. 예측을 하기 위한 단어의 데이터를 수치화를 시켜서 예측이 가능한 형태로 바꿔주는 작업니다. 예를 들어 "The dog bark in the garden"을 기계가 이해할 수 있도록 수치적으로 표현하면 다음과 같다. The, dog , bark, in, the, garden과 같이 언어별로 분류한 후 특정 위치만 1로 나타내는 원-핫 인코딩을 통해 다음과 같이 표현할 수 있다.

Word2 Vec
Word2 Vec 방식은 위에서 설명한 Word Embedding 방식에서 조금 더 발전한 방식이다. Word Embedding 방식은 원-핫 인코딩을 통해서 얻은 원-핫 벡터는 표현하고자 하는 단어의 인덱스의 값만 1이고, 나머지는 모두 0으로 표시한다. 그래서 각 단어 간의 유사성을 반단하기는 힘든 희소 행렬 표현 방식이다. 그래서 단어 간의 유사성을 반영하여 벡터화하여서 처리한다.
이렇게 기본적인 Word2 Vec에 대한 사전 지식을 설명했다. 이제 이 알고리즘의 작동 방식을 말하자면 CBOW Embedding과 Skip-Gram 방식 2가지가 있다. 서로 작동 방식은 비슷하지만 결과가 반대이다.
- CBOW(Continuous Bag of Words) Embedding : 주변에 있는 단어를 이용해 중간에 있는 단어를 예측
- Skip - Gram : 중간에 있는 단어로 주변 단어를 예측하는 방법
CBOW(Continuous Bag of Words)
CBOW에서는 신경망 언어 모델(Neural NetWork Language Model, NNLM)을 사용한다. NNLM은 원래 1개의 단어로부터 다음에 오는 단어를 예측할 때 주로 사용된다. 하지만 CBOW Embedding은 신경망 언어 모형을 사용하면서 복수 단어 문맥에 대한 문제, 즉 여러 개의 단어를 나열한 후 이와 관련된 단어를 추정하는 문제를 해결하기 위해 고안되었다.
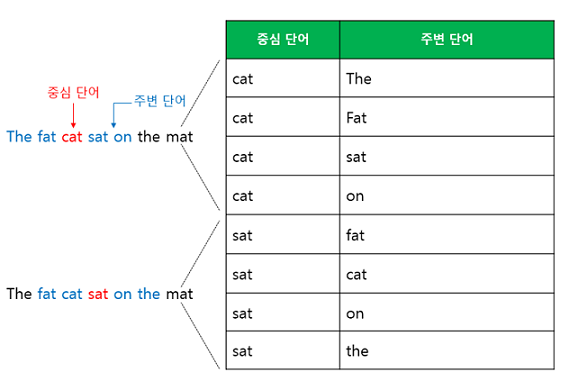
- 예문 : "The fat cat sat on the mat"
예를 들어서 갖고 있는 코퍼스에 위와 같은 예문이 있다고 합시다. ['The', 'fat', 'cat', 'on', 'the', 'mat']으로부터 sat을 예측하는 것은 CBOW가 하는 일입니다. 이때 예측해야 하는 단어 sat을 중심 단어(center word)라고 하고, 예측에 사용되는 단어들을 주변 단어(context word)라고 합니다.
중심 단어를 예측하기 위해서 앞, 뒤로 몇 개의 단어를 볼지를 결정해야 하는데 이 범위를 윈도(window)라고 합니다. 예를 들어 윈도우 크기가 2이고, 예측하고자 하는 중심 단어가 sat이라고 한다면 앞의 두 단어인 fat와 cat, 그리고 뒤의 두 단어인 on, the를 입력으로 사용합니다. 윈도우 크기가 n이라고 한다면, 실제 중심 단어를 예측하기 위해 참고하려고 하는 주변 단어의 개수는 2n입니다.
윈도로 중심단어와 주변단어의 범위가 지정되면 옆으로 움직여서 주변 단어와 중심 단어의 선택을 변경하며 데이터 셋을 만든다. 이 방식을 '슬라이딩 윈도(Sliding Window) '방식이라고 한다.
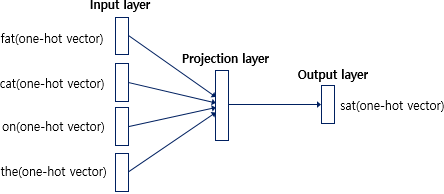
위의 그림은 CBOW의 인공 신경망을 간단하게 도식화한 그림이다. 다른 딥러닝 모델과 비슷하게 은닉층과 출력을 따로 지정하고 나누어서 작동하고 그리고 입력값은 원-핫 벡터의 형식으로 입력한다.
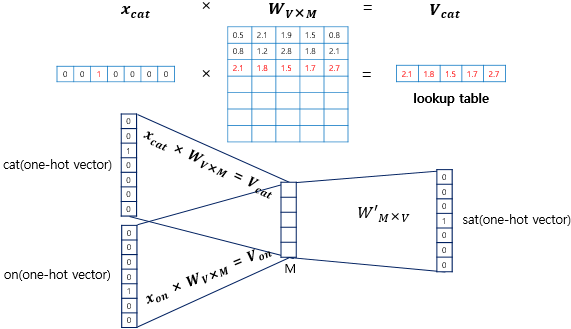
딥러닝 모델이니 만큼 인력층 행렬을 가중지최 곱하여 은닉층에 맞게 값을 임베딩 해주고 그 이후에 은닉층에서 출력층으로 가는 가중치를 곱해줌으로써 결괏값이 나온다.
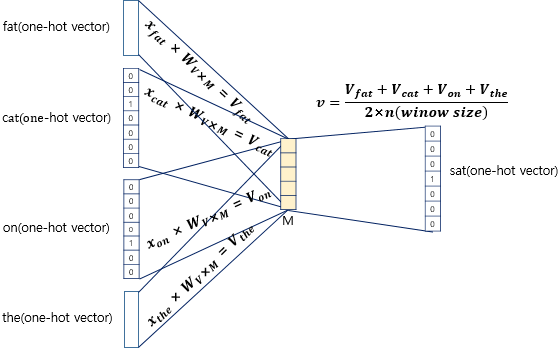
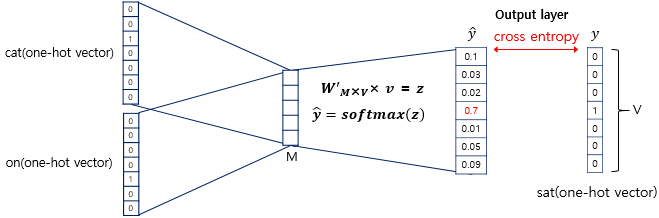
이제 중간값을 찾기 위해 옆의 단어를 입력값으로 입력을 했다면 마지막 반한환 벡터의 soft max 함수를 적용시킨다. 그렇게 된다면 확률값으로 어떤 값이 타깃인지를 표시. 그 이후에 입력층과 같은 형식의 값을 반환한다. 이후에는 결과값을 가지고 CBOW 손실 함수로 크로스 엔트로피 함수를 사용하여서 얻은 손실값을 가지고 역전파 방식을 통해 가중치를 조정한다.
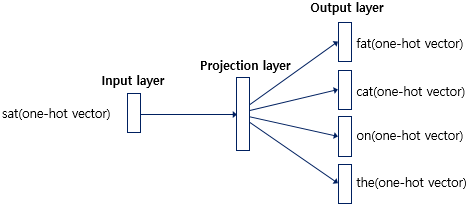
Skip - Gram
Skip - Gram 방식에서는 주변 단어에서 예측하는게 아니라 중심 단어를 가지고 주변 단어를 예측하는 방식이다. 이전 CBOW 방
단순한 단어의 빈도를 이용해 문서를 특성화하던 수준에서 단어를 원 - 핫 인코딩으로 변경한 후 신경망 모델을 적용해 중심 단어와 주변 단어 간의 관계를 파악할 수 있는 수준으로 발전하고 있다.
'Deep Learning > NLP' 카테고리의 다른 글
| [Deep Learning] GNN - Graph Neural Networks(미완) (0) | 2023.07.01 |
|---|---|
| [NLP] 워드 임베딩(Word Embedding 1/2)-BOW,Count Vector (0) | 2022.12.28 |
| [NLP] 워드 임베딩(Word Embedding 1/2) - TF-IDF(Term Frequency - Inverse Document Frequency) (0) | 2022.12.01 |
| [NLP] 레벤슈타인 거리(Levenshtein Distance) (0) | 2022.11.17 |
| [NLP] 텍스트 분석이란? (0) | 2022.11.16 |


