
목록이미지 (4)
운동하는 공대생
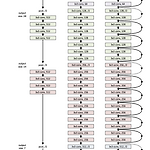 [논문]Resnet-Deep Residual Learning for Image Recognition
[논문]Resnet-Deep Residual Learning for Image Recognition
논문 https://arxiv.org/abs/1512.03385v1 Deep Residual Learning for Image Recognition Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with arxiv.org 0. Abstract 저자는 DNN 모델을 훈련을 할 때 residual functio..
 [Computer Vision] 컴퓨터 비전과 딥러닝 4장- 대화식 분할, 영역 특징
[Computer Vision] 컴퓨터 비전과 딥러닝 4장- 대화식 분할, 영역 특징
이전까지는 영역에 대한 분할을 자동적으로 영상 전체에서 진행을 하였다. 하지만 이런 분할을 사용자가 원하는 분할을 하지 못하는 문제가 있었고 이런 문제를 해결하기 위해서 대화식 분할의 아이디어가 되었다. 1. 대화식 분할 1.1 능동 외곽선 능동 외곽선의 원리는 초기 곡선에서 시작해서 최적의 상태를 능동적으로 찾아가는 방식이다. - 수식 E(internal) = 내부 에너지로 곡선이 매끄러운 모양이 되도록 유도 E(image) = 영상 에너지는 물체의 경계에 에지가 나타난다는 사실에 기반하여 곡선이 에지에 위치하도록 유도 E(domain) = 도메인 에너지는 분할하려는 특정 물체의 모양 정보를 잘 유지하도록 유도 이렇게 에너지들의 총합들을 계산하고 이것을 최소가 되도록 하여 최적화를 진행한다. 1.2 G..
 [Computer Vision] 컴퓨터 비전과 딥러닝 - 3장
[Computer Vision] 컴퓨터 비전과 딥러닝 - 3장
1. Intro 컴퓨터 비전과 딥러닝 책의 3장 내용을 정리한 내용입니다. 3장에서는 이미지, 영상 데이터를 어떻게 데이터화시키는지를 설명하는 장이다. 이미지나 영상 데이터는 고차원은 다분광, 초분광 같은 영상들도 있지만 보통 RGB로 구성된 영상으로 예시를 많이 진행했다. 2. 이진 영상 2.1 이진화 이진화란 maxtrix 형식으로 표현된 데이터에서 임곗값 T를 기준으로 T 보다 크면 1 적으면 0 이런 식으로 데이터를 단순히 이진화시킨다. 2.2 오츄 알고리즘 전체 이미지에서 적정한 임곗값을 먼저 계산하여 임곗값을 정한다. 2.3 연결 요소 connected component labeling 이라고도 하며 근처에 있는 같은 데이터를 연결 지어서 분류해 주는 방식이다. 2.4 모 폴로지 영상을 변환하..
 [Transformers] Layoutlmv2 모델로 이미지 텍스트 layout 분류
[Transformers] Layoutlmv2 모델로 이미지 텍스트 layout 분류
1 Intro 이미지 분석, 텍스트 분석 등 다양하게 딥러닝 모델과 프로세스들이 각광받고 있는 요즘 Text Extraction 즉 이미지에서 텍스트 정보를 인식하고 데이터화하는 방식에 대한 연구를 진행하였고 내가 사용하였던 layoutlmv2 모델의 이론과 그리고 코드를 리뷰해보려고 한다. 2 Process 이미지에서 텍스트를 추출하는 방식을 간단하게 도식화 하자면 아래의 그림과 같다. 먼저 아래의 그림처럼 이미지에서 text 즉 글씨의 정보를 OCR 기법을 이용하여 단어의 위치와 범위를 bounding box 형식으로 구분하여 지정을 한다. 그 이후에 위치정보와 텍스트 정보를 이요하여서 Layoutlmv2 모델에 적용하고 모델을 학습시킨 후 그 단어가 어떤 layout 에 지정이 되는지를 예측하는 방..