
운동하는 공대생
[Transformers] Layoutlmv2 모델로 이미지 텍스트 layout 분류 본문
1 Intro
이미지 분석, 텍스트 분석 등 다양하게 딥러닝 모델과 프로세스들이 각광받고 있는 요즘 Text Extraction 즉 이미지에서 텍스트 정보를 인식하고 데이터화하는 방식에 대한 연구를 진행하였고 내가 사용하였던 layoutlmv2 모델의 이론과 그리고 코드를 리뷰해보려고 한다.
2 Process
이미지에서 텍스트를 추출하는 방식을 간단하게 도식화 하자면 아래의 그림과 같다. 먼저 아래의 그림처럼 이미지에서 text 즉 글씨의 정보를 OCR 기법을 이용하여 단어의 위치와 범위를 bounding box 형식으로 구분하여 지정을 한다. 그 이후에 위치정보와 텍스트 정보를 이요하여서 Layoutlmv2 모델에 적용하고 모델을 학습시킨 후 그 단어가 어떤 layout 에 지정이 되는지를 예측하는 방식으로 프로세스가 진행하였다.

- 이미지 데이터 OCR 을 통해 텍스트 데이터 추출( Naver Ocr API를 사용했으면 Hugging Face에서 Layoutlmv2 모델에서도 기본 OCR을 사용하는 것도 가능하다.)
- Text Segmentation으로 텍스트의 위치 정보를 생성
- Pre-trained Layoutlmv2 모델을 활용하여 텍스트의 layout을 예측
이론은 아래의 논문을 참고하였다.
LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding
LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding
Pre-training of text and layout has proved effective in a variety of visually-rich document understanding tasks due to its effective model architecture and the advantage of large-scale unlabeled scanned/digital-born documents. We propose LayoutLMv2 archite
arxiv.org
2.1 Layoutlmv2 Model Architecture
-Text embedding
위의 사진을 참조하면 텍스트 데이터를 WordPiece 로 쪼개서 토큰화하여 모델에 적용한다. 이는 OCR 이후의 과정읠 text를 토큰화한 것이다. 그래서 각 단어의 시작과 끝점을 [CLS] [SEP]라고 표시를 해두었으면 추가로 [PAD]라는 표시로 마지막 문장의 위치를 표시하였다. 이는 텍스트에 대한 번위를 구분하고 또 단어 단어를 분리를 해주는 효과가 있다. 그리고 이후에는 텍스트의 위치를 표시하는 positional embedding을 추가로 하여서 텍스트의 정보, 텍스트의 위치정보도 같이 임베딩을 시켜준다. 마지막으로 어쩐 layout인지를 지정하는 segment embedding까지 같이 3개의 정보를 임베딩하여 사용한다. 이는 텍스트를 토큰화하는
과정에서 반드시 필요한 과정이고 토큰화된 데이터는 3개의 임베딩 데이터를 합친 것과 같다.
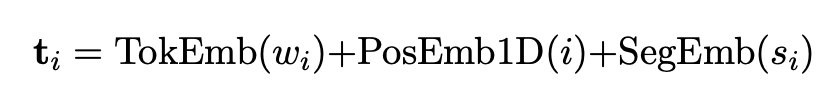
-Visual embedding
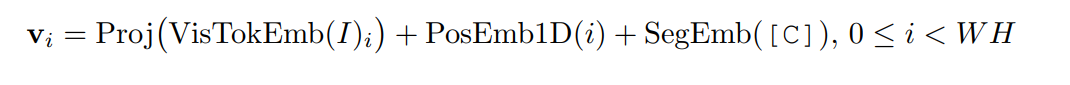
-Layout embedding
Layout embedding은 데이터를 모델에 맞춰서 정규화를 해주는 과정이다. x, y 좌표가 기준이 되며 layout 모델에서는 [0,1000] 범위로 bounding box의 좌표 위치를 정규화하고 축소시키거나 확대한다.
2.2 pre-training task
-Masked Visual-Language Mode
Masked Visual-Language Model (MVLM)은 레 모델의 핵심 구성 요소 중 하나로, 시각 및 텍스트 입력에서 자기 지도 학습 방식으로 모델이 학습할 수 있한다. MVLM은 원래 BERT 모델에서 사용되는 마스크 된 언어 모델링 목적과 유사한 마스크된 언어 모델링 목적을 사용하여 학습된다.
학습 중에 입력의 일부 토큰이 무작위로 마스크 처리되며, 모델은 남아 있는 토큰의 문맥에 기반하여 마스크된 토큰의 원래 값을 예측하도록 학습됩니다. LayoutLMv2에서는 MVLM이 이 접근 방식을 확장하여 무작위로 선택된 이미지 패치를 마스크 처리하고 MVLM의 입력으로 사용하는 마스크된 시각적 토큰을 포함한다.
MVLM은 입력 텍스트와 남아 있는 마스크 처리되지 않은 시각적 토큰에 의해 제공되는 문맥에 기반하여 마스크 처리된 시각적 토큰의 원래 값을 예측하도록 학습합니다. 이를 통해 모델은 문서의 시각적 및 텍스트 콘텐츠의 공동 표현을 학습할 수 있으며, 이후 문서 레이아웃 분석, 표 감지 및 명명된 개체 인식과 같은 하위 작업에 사용할 수 있다.
-Text-Image Alignmnet
LayoutLMv2 모델에서 Text-Image Alignment(텍스트-이미지 정렬)은 레이아웃 분석을 위한 핵심 구성 요소 중 하나입니다. 이 기능은 텍스트와 이미지 사이의 정렬을 식별하고 이를 통해 텍스트와 이미지 간의 관계를 모델링합니다.
이를 위해 LayoutLMv2 모델은 컨볼루션 및 어텐션 메커니즘을 결합하여 다단계적인 텍스트-이미지 정렬 프로세스를 수행합니다. 먼저, 텍스트와 이미지의 각 세그먼트에서 모델은 개별적으로 특성을 추출합니다. 그런 다음, 다중 모달 어텐션 계층을 사용하여 텍스트와 이미지 간의 관계를 모델링합니다.
이 프로세스는 여러 모드로 수행됩니다. 먼저, LayoutLMv2는 텍스트와 이미지 세그먼트를 묶어 샘플을 만들고, 각 샘플에서 텍스트-이미지 정렬을 학습합니다. 이 학습 과정에서 모델은 텍스트 및 이미지 세그먼트 간의 정렬 관계를 학습하고, 이를 기반으로 더 큰 문서 수준에서 레이아웃 분석을 수행할 수 있습니다.
텍스트-이미지 정렬 기능은 레이아웃 분석과 같은 다양한 문서 분석 작업에서 중요한 역할을 합니다. 이를 통해 모델은 문서의 레이아웃 및 콘텐츠를 보다 정확하게 이해하고, 이를 통해 자동 문서 처리 및 분류와 같은 다양한 응용 프로그램을 지원할 수 있습니다.
-Text-Image Matching
LayoutLMv2 모델에서 Text-Image Matching(텍스트-이미지 매칭)은 레이아웃 분석을 위한 핵심 구성 요소 중 하나입니다. 이 기능은 텍스트와 이미지 간의 의미적 일치를 식별하고, 이를 통해 텍스트와 이미지 간의 관계를 모델링합니다.
이를 위해 LayoutLMv2 모델은 다중 모달 어텐션 메커니즘을 사용하여 텍스트와 이미지 간의 매칭을 수행합니다. 이 메커니즘은 텍스트와 이미지에서 추출된 특성을 기반으로 모델이 텍스트와 이미지 간의 관계를 식별하는 데 사용됩니다.
Text-Image Matching은 텍스트와 이미지의 일치도를 측정하고 이를 통해 텍스트와 이미지 간의 관계를 모델링합니다. 이를 통해 모델은 문서의 레이아웃과 콘텐츠를 더 정확하게 이해하고, 다양한 응용 프로그램에서 이를 활용할 수 있습니다.
이러한 Text-Image Matching 기능은 레이아웃 분석 및 다른 문서 분석 작업에서 중요한 역할을 합니다. 이를 통해 모델은 문서의 콘텐츠와 레이아웃을 보다 정확하게 파악하고, 이를 활용하여 다양한 자동 문서 처리 및 분류 작업을 수행할 수 있습니다.