
운동하는 공대생
[논문] Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve 본문
[논문] Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
운동하는 공대생 2024. 8. 5. 18:37논문
https://arxiv.org/abs/2403.02310
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve
Each LLM serving request goes through two phases. The first is prefill which processes the entire input prompt and produces the first output token and the second is decode which generates the rest of output tokens, one-at-a-time. Prefill iterations have hi
arxiv.org
1. Introduction

본 논문에서는 기존의 LLM inference schedulering 모델에 대한 문제점을 보안하는 방식을 통해서 새로운 방식을 제시하였다. 먼저 LLM inference에서 prompt를 처리하는 prefill 단계와 토큰을 autoregressive 하게 처리하는 token을 생성하는 decode 부분으로 나누어 생각하며 여기서 발생하는 GPU 연산의 비효율을 이야기합니다.
현재 사용하고 있는 schedulers 들에서는 prefill-prioritizing 방식과 decode-prioritizing 방식을 통해서 연산을 처리합니다. 기존의 방식들을 간단하게 설명을 해보겠다.
Decode-prioritizing(FasterTransformer)
이 방식은 batch에 들어있는 모든 request에 대한 prefill 과정 및 decode 과정을 모두 수행을 하고 그 이후에 새로운 request를 받는 방식으로 동작합니다. 그래서 새로운 request 에 대한 prefill 작업은 수행되지 않는다. 이런 방식은 새로 들어오는 request가 decode 연산에 영향을 주지 않음으로 time between tokens(TBT) 을 최적화해주는 효과를 가진다.
하지만 이 방식은 throughput 에 성능은 높지 않다. 그 이유는 배치 안에서 하나의 request가 빨리 끝나더라도 모든 batch의 request 가 끝나기를 기다리기 때문이다.
Prefill-prioritizing(vLLM, Orca)
이 방식에서는 이전 방식과 다르게 prefill 연산을 우선적으로 처리르 하기 때문에 GPU가 연산이 가능하다면 새로운 request를 받고 prefill 연산을 먼저 수행합니다. 그래서 batch 사이즈를 늘릴 수 있어서 throughput이 높지만 prefill 과정은 연산 시간이 많이 걸리기 때문에 높은 latency가 실행 중인 decode에 영향을 주기 때문에 발생한다. 그래서 prefill 연산을 진행하면서 실행 중인 decode 연산이 멈추는 generation stall 현상이 발생한다.
2. Background
2.1 LLM Inference Process
Autoregressive decoding
LLM inference는 2단계로 구성되어 있는데 prefill에서는 모델의 input prompt가 들어오고 첫 토큰이 생성되는 시간 까지를 이야기 한다. 그리고 decode는 prefill 이후에 토큰을 생성하는 과정을 의미한다. 그리고 EOS 토큰이 생성될때 비로소 decode가 끝이 난다.
보통 LLM prompt는 100~1000개의 토큰을 input으로 받으며 한 번의 iteration에 병렬적으로 처리가 된다. 하지만 반대로 decode 에서는 한번의 iteration에서 한 개의 토큰만을 처리한다.
2.2 Scheduling Policies for LLM Inference
Request-level batching(Decode-prioritizing)
decode-prioritizing 방식은 batch에 있는 request들을 선택하고 batch에 있는 모든 request가 수행이 될 때까지 실행된다. 여기서 각각의 request들은 차이가 많이 있다. 하지만 여기서 작은 크기의 request는 크기를 맞추기 위해서 0으로 채워 사이즈를 맞춘다. 하지만 여기서 추가적인 latency가 발생한다.
Iteration-level batching(Prefill-prioritizing)

이 방식은 최근 등장한 Orca 방식에서 사용하는 방식으로 GPU의 연산 처리가 가능하다면 우선적으로 request를 받아서 prefill 연산을 진행한다. 이 방식은 throughput을 증가시켜 준다.
3. Motivation
3.1 Cost Analysis of Prefill and Decode
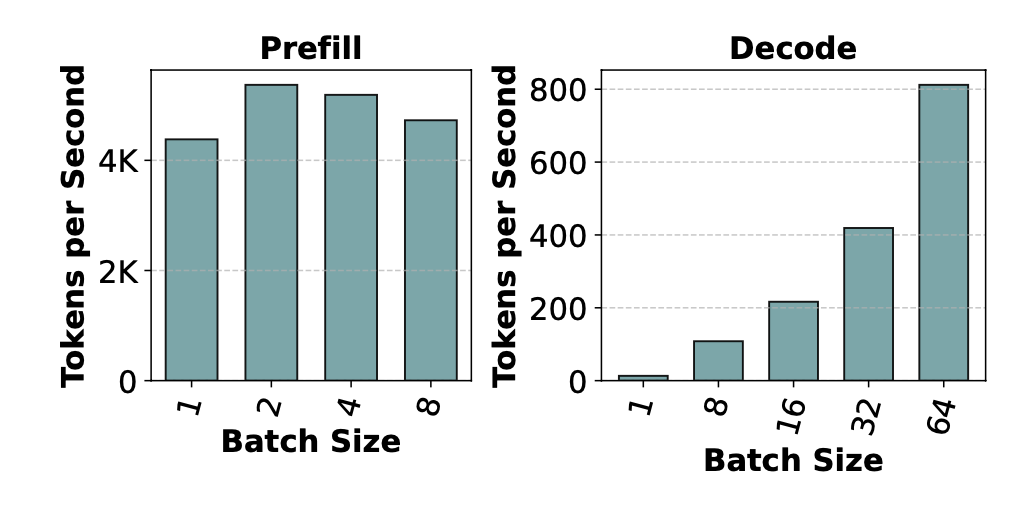
이전에 설명을 했듯이 prefill 단계에서는 GPU연산이 병렬적으로 한 번에 처리가 가능하지만 decode 단계에서는 한 개의 토큰당 한번의 연산이 이루어진다. 위에 나오는 그래프처럼 prefill 에서는 batch size 가 늘어난다고 하더라도 비교적 일정한 성능을 보인다. 이것은 GPU 연산 처리의 성능 때문에 batch 를 늘리더라도 prefill 에서는 높은 처리율을 보이지만 decode에서는 한개의 토큰당 한개의 연산을 수행함으로 batch가 늘어나면 늘어날수록 linear 한 증가를 보인다.
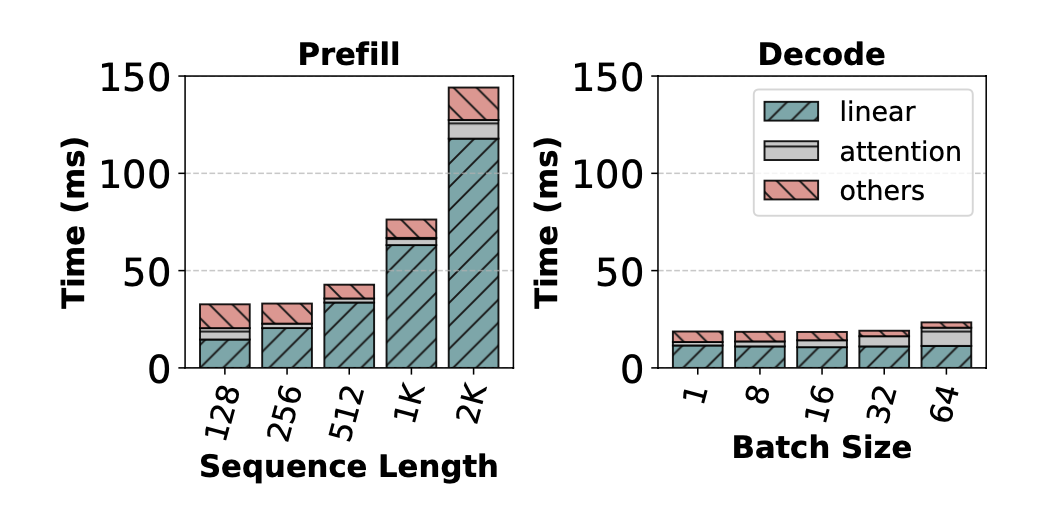
prefill은 prompt의 sequence 길이에 따라서 처리하는 속도가 많이 차이가 난다. 하지만 decode에서는 batch 사이즈가 커지더라도 많은 차이를 보이지 않는다.
Low Compute Utilization during Decodes
LLM inference에서는 linear 연산에서 많은 시간을 소유한다. Matrix 연산은 kernel에서 memory access와 곱 연산이 동시에 일어납니다. T=max(Tmath,Tmem) 이 total 실행 시간이라고 한다면 여기서 메모리 접근 시간이랑 연산 시간 중에서 더 오래 걸리는 시간을 총 소유 시간으로 계산한다. 하지만 여기서 Tmath<Tmem 일 때 메모리 접근 시간이 더 많이 걸리는 상황을 memory-bound라고 이야기를 하고 모델에 대한 연산이 적은 MFU 가 적다고 이야기를 한다. 하지만 반대의 경우에는 compute-bound라고 하며 model bandwidth utilization이 작다고 한다. 그래서 Tmath=Tmem 인 상황이 연산과 메모리 bandsidth 활용이 최대화되었다고 말한다.
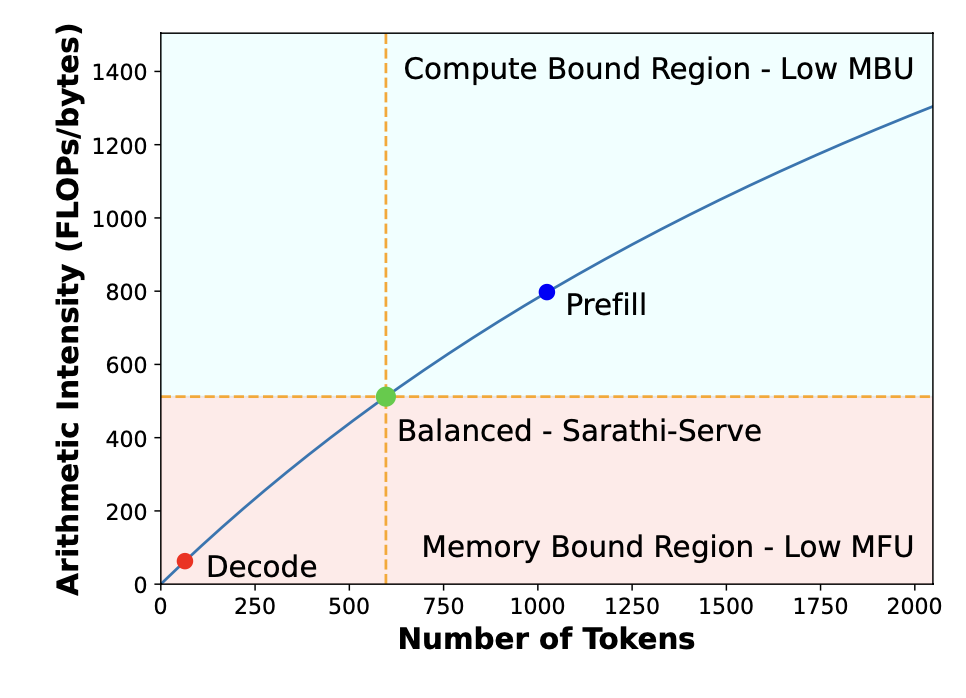
그래서 prefill과 decode 연산을 본다면 decode 부분은 Low MFU 상황이고 prefill은 Low MBU 상황이라고 이야기를 한다.
3.2 Throughput-Latency Trade-off
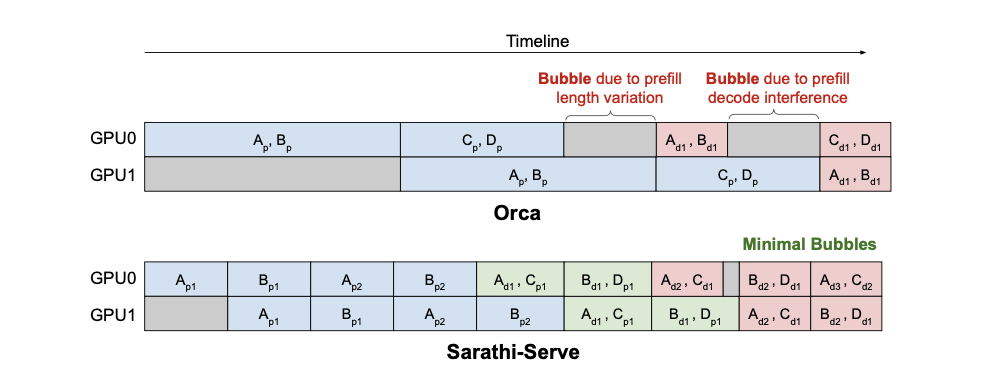
앞서 설명했듯이 iteration-level batching은 시스템의 throughput을 높이지만 prefill을 처리하는 과정에서 generation 하는 과정의 멈춤이 발생한다(generation stall).
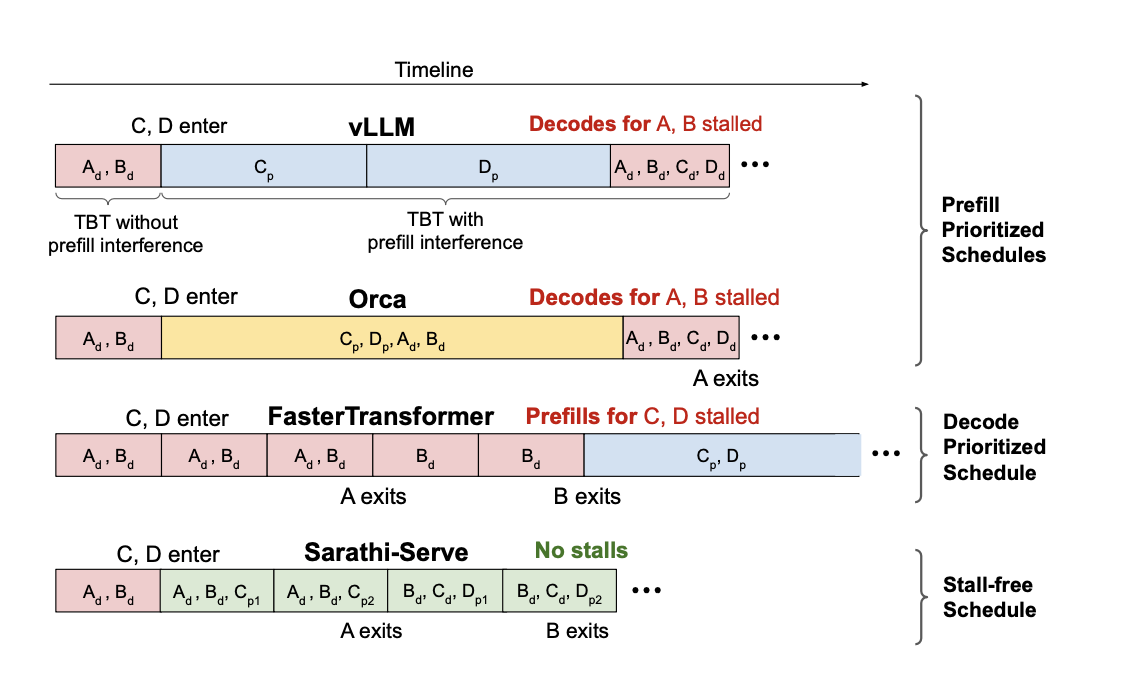
vLLM 은 prefill prioritizing 방식을 사용함으로 새로운 request가 들어오면 prefill을 먼저 수행함으로 decode 해야 하는 request에 대한 stall이 생긴다. 그리고 Orca, FasterTransformer 또한 추가적인 request에 대한 stall 이 발생함을 볼 수 있다.
반대로 request-level batching 시스템은 위에서 보인 그림처럼 모든 요청이 끝나야 prefill 작업을 진행함으로 추가적인 request에 대한 latency가 발생한다. 즉 낮은 throughput을 가지더라도 TBT에 대한 성능은 높다.
즉 기존에 가지고 있는 문제는 throughput과 latency에 대한 tradeoff이다.
3.3 Pipeline Bubbles waste GPU Cycles
Pipeline parallel vs Tensor parallel
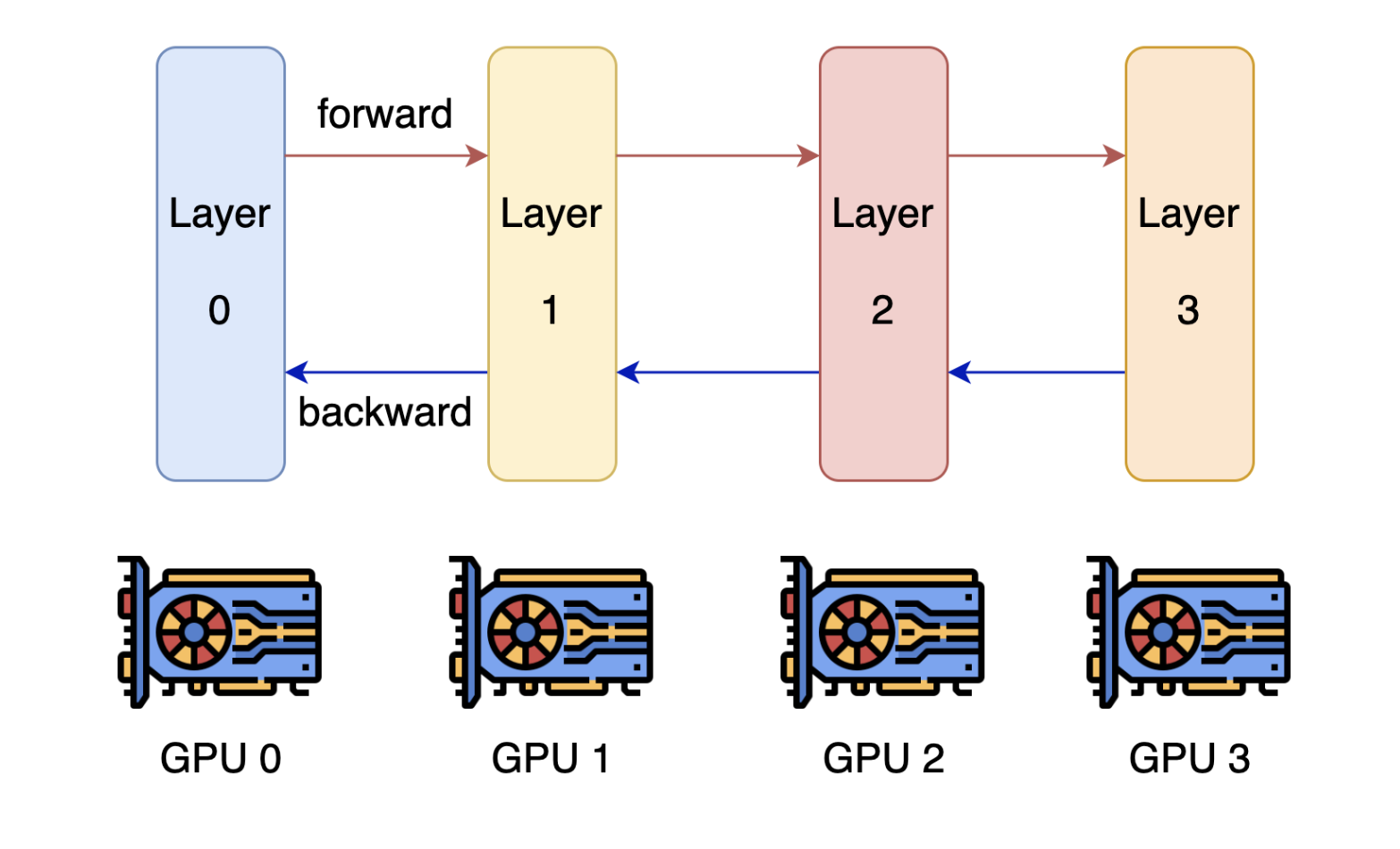
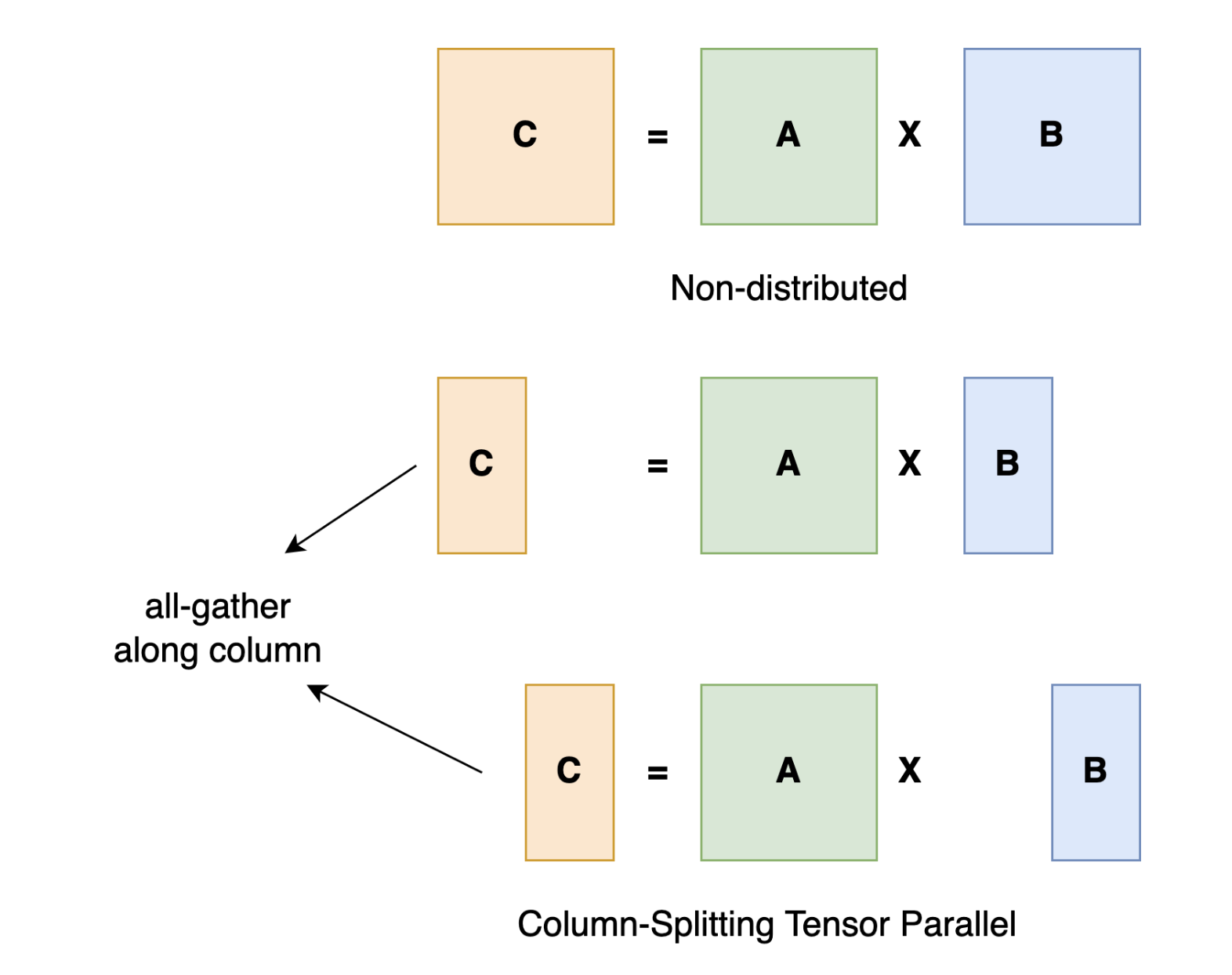
pipeline parallel 방식이 tensor parallel 방식보다 overhead가 적어서 주로 사용되지만 요청을 처리하면서 추가적인 bubble이 발생하게 된다. 그리서 GPU cycle에 대한 비효율을 야기한다.
- TP(Tensor Parallelism): 모델의 서로 다른 부분을 각 GPU가 동시에 처리. 높은 통신 비용(all-reduce 연산). 단일 노드 내에서 고대역폭 인터커넥트 사용 시 선호.
- PP(Pipeline Parallelism): 모델을 레이어 단위로 나누어 각 GPU가 일부 레이어를 처리. 낮은 통신 비용(포인트 투 포인트 통신). 노드 간 배포 시 효율적.
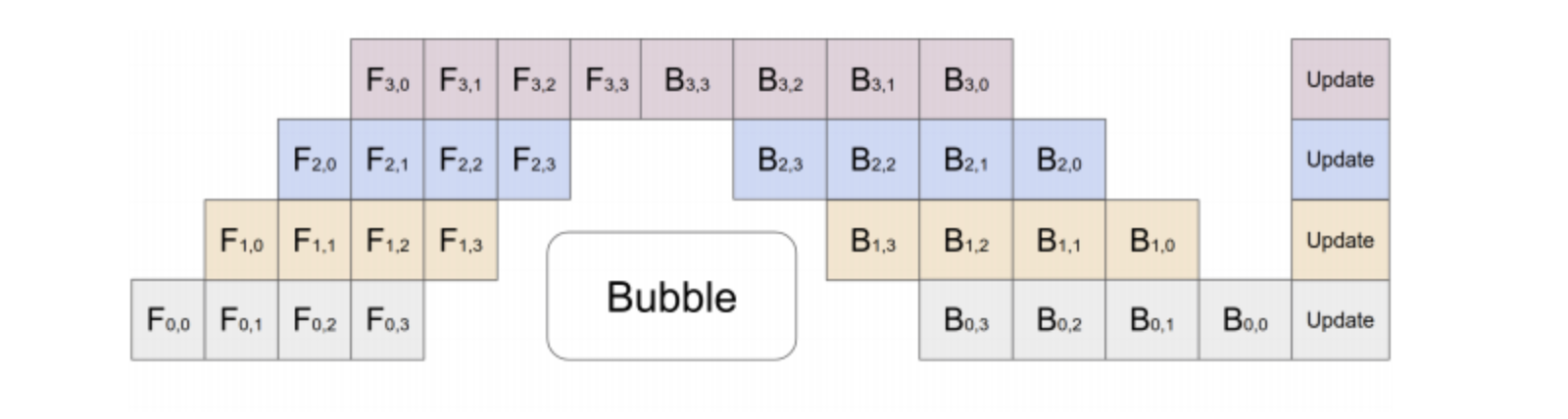
Orca에서 주로 사용하며 이런 방식은 각각의 request의 micro-batch 에 대한 연산이 각각 다른 LLM의 특성 때문에 영향을 많이 받는다. 아래의 그림으로 설명을 해보자면 Orca 에서 각각의 GPU가 pipeline parallel 방식을 통해서 request microbatch를 처리한다고 할 때 bubble을 최소화하더라도 다음 연산에 대한 bubble이 반드시 발생한다.
bubble 발생 경우
1) 서로 다른 크기(request length)의 차이로 발생하는 prefill bubble
2) prefill과 decode의 연산 차이로 생기는 bubble
3) micro-batch에서 서로 다른 토큰의 decode 연산 처리 속도 때문에 발생하는 버블
종합
Takeaway-1
batch를 나누는 것은 prefill과 decode에 다른 영향을 주는데 prefill에서는 거의 영향이 없지만 decode에서는 영향을 많이 끼친다.
Takeaway-2
decode batchs는 memory-bound 상황에서 연상이 진행됨으로 연산에 대한 Latency는 많이 발생하지 않는다.
Takeaway-3
prefill과 decode의 간섭 때문에 현재의 LLM inference schedulers는 throughput과 latency 사이의 tradeoff 가 존재하며 현재는 prefill-prioritizing schedules 방식을 사용하여 높은 처리율을 가지도록 한다.
Takeaway-4
pipeline-parallelism을 사용함에 있어서 연산 속도의 차이 때문에 bubble 이 발생한다.
4. Sarathi-Serve: Design and Implementation
4.1 Chunked-prefills
앞에서 설명을 했듯이 decode batch들은 memory bound 상황에서 적은 계산 강도를 가지고 있다. 그래서 이것은 추가적인 decode연산을 가능하게 합니다. 간단하게 말해서 memory bound decode 연산과 compute bound prefill 연산을 혼합하여 hybrid batch를 만드는 게 가능하다. 그래서 다양한 크기의 prompt를 처리하기 위해서 높은 TBT latency를 발생시킨다. 그래서 이것을 해결하기 위해서 큰 prefill연산을 작은 chunked-prefills로 나누어서 처리를 한다.
여기서 2가지에 주의를 해야 하는데 첫 번째는 GPU 연산에 효율을 위해서 적절한 sequence 길이를 설정한다, 두 번째는 큰 사이즈의 prompt는 작은 단위로 쪼개는 게 가능하며 작게 나눈 크기는 GPU 연산에 최대한의 효율을 가지는 크기로 나눈다.
4.2 Stall-free batching

코드를 보면 line 6~8에서 처리 중인 decode 토큰을 확인하고 line 10 ~12 까지는 prefill이 진행 중인 chunk 가 존재하는지를 확인한다. 그리고 마 짐 간으로 line 13~20까지 요청을 받아들여 작업을 진행한다.

4.3 Determining Token Budget
그렇자면 이런 input token에 대한 budget은 어떻게 지정을 하는지 설명을 해보겠다. TBT를 최소화하는 관점에서 본다면 token 사이즈를 작게 해서 prompt를 chunked 하는 게 맞지만 그렇게 된다면 GPU 활용도가 낮아지며 KV-cache에 접근하는 추가적인 overhead가 발생하게 된다.
왜냐하면 프로세스가 진행되기 위해서는 이전에 prompt chunk 데이터가 저장되어있어야 하니 이것은 N개의 chunk 가 존재한다면 한 번의 chunk가 N-1번의 KV-cache 접근이 필요하다 그리고 그다음 chunk는 N-2번의 접근을 할 것이다. 이것은 많은 오버헤드를 일으킨다.
그래서 적절한 Budget을 찾는 것이 중요하다.
5. Evaluation
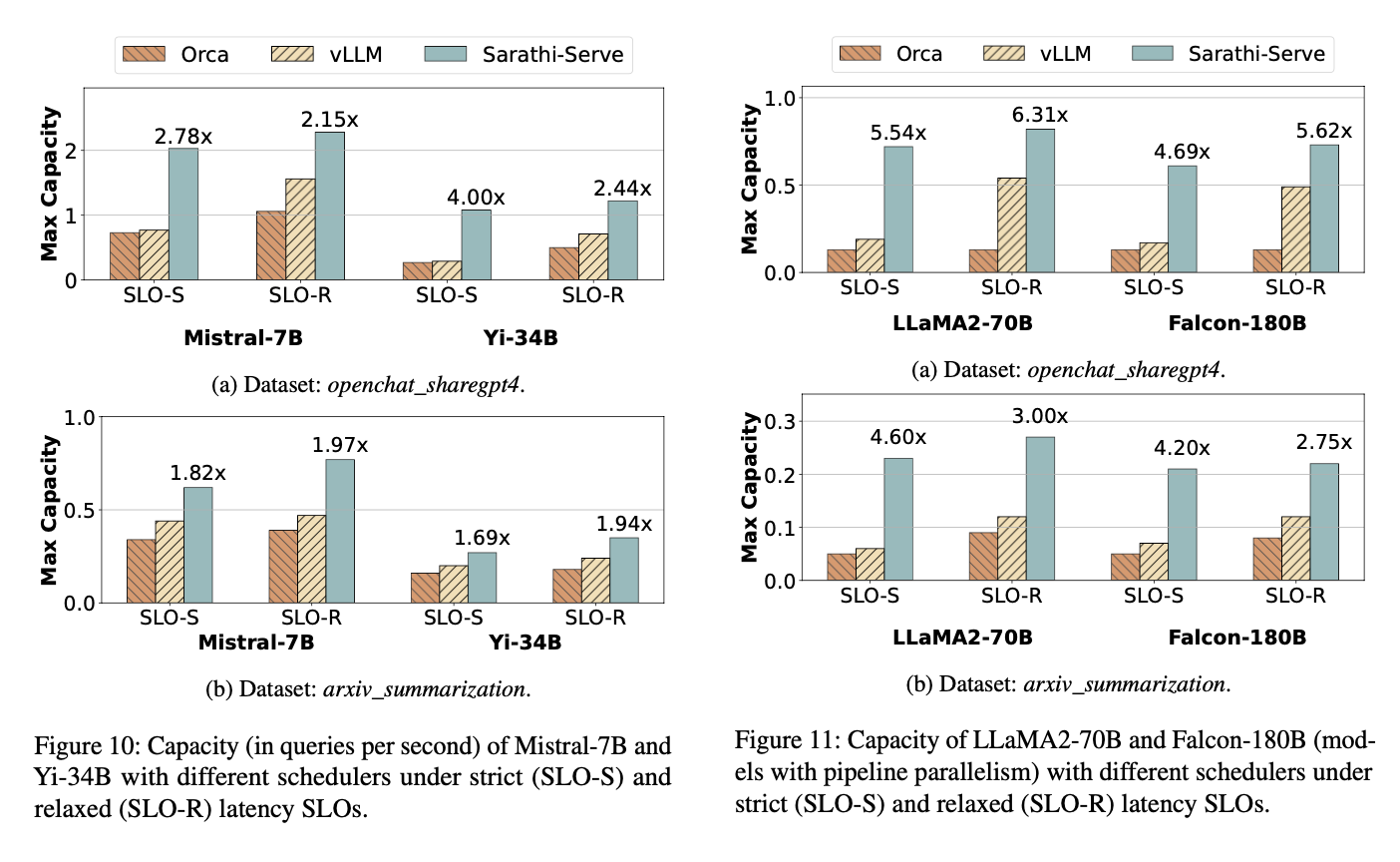
Service Level Objective(SLO) 시스템에서 기대하는 가용성의 목표로 시스템이 요구하는 성능을 말한다. 이것을 strict, relaxed로 나누어서 요구하는 성능의 정도를 따져서 구분을 하는데 다른 모델에 비해 높은 성능을 보인다.
'논문' 카테고리의 다른 글
| [논문]LeaFTL: A Learning-Based Flash Translation Layerfor Solid-State Drives (1) | 2024.11.09 |
|---|---|
| [논문] Compressing Large Language Models by Joint Sparsification and Quantization (0) | 2024.11.07 |
| [논문]LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS (0) | 2024.05.17 |
| [논문] Deep Learning and the Information Bottleneck Principle (2) | 2024.01.21 |
| [논문] DELIGHT: Deep and Light-Weight Transformer (1) | 2023.10.03 |

