
운동하는 공대생
[논문] DELIGHT: Deep and Light-Weight Transformer 본문
논문
https://arxiv.org/abs/2008.00623v2
DeLighT: Deep and Light-weight Transformer
We introduce a deep and light-weight transformer, DeLighT, that delivers similar or better performance than standard transformer-based models with significantly fewer parameters. DeLighT more efficiently allocates parameters both (1) within each Transforme
arxiv.org
1. Introduction
이 논문에서 제시하는 DeLighT 모델은 기존 transformer 방식에서 multi-head attention과 feed-forward 방식은 single head attention과 light-weight feed-forward로 변경하여서 기존보다 전체적인 네트워크의 파라이터를 줄였다. 깊이와 넓이를 input size와 분리하여 output 근처의 블록을 조정하는 게 가능하다고 이야기했다. 그리고 machine translation과 language modeling 2가지 분야에서 기존 transoformer 방식보다 비슷하거나 더 좋은 성능을 보인다고 했다.
2. Related Work
Improving transformers
transformer 모델의 구조를 향상하기 위해서는 self attention 구조에서 긴 input 시퀀스를 사용하는 방법이고 이것이 이번 논문의 모델에 적용이 가능하다고 하였다. 그리고 두 번째로는 multi-head 방식에서 그 수를 증가시켜서 중복된 정보를 늘어나게 되고 고정된 gead의 수는 지정된 패턴으로 성능을 향상한다. 세 번째로는 더 나은 표현으로 모델을 학습하는 방식이다. 이런 연구는 다른 변형을 통해서 transformer의 표현성을 높이기 위해서 이다. 예를 들어 convolution을 사용한 gated linear units, multi-branch feature extractors 같은 방식이 있다. 이런 방식과 다르게 DeLight는 파라미터를 조금 더 효과적으로 블록레벨 DeLight transformation과 block-wise 스케일링을 한다.
Model scaling
Model scaling은 모델의 성능을 향상하기 위한 가장 일반적인 방식이다. 차원을 너비나 깊이로 더 깊이 쌓는다고 하더라도 그것을 차선의 해결법이다. 그래서 본 논문에서는 block-wise sclaing을 통해서 다양한 사이즈의 블록을 사용하고 효율적인 파라미터를 할당한다. 논문의 결과에서 더 얕고 좁은 구조를 input 근처에 배치하고 깊고 넓은 블록을 ouput근처에 배치하여서 최고의 성능을 내게 하였다. 그리고 block-wise scaling 이 단순히 model scaling 한 거보다 더욱 성능이 좋았다. 우리는 합성곱 신경망(CNNs)도 입력 부분에서는 더 얕고 좁은 표현을 학습하며, 출력 부분에서는 더 깊고 넓은 표현을 학습한다. CNNs (예: He et al. 2016의 ResNet)과는 달리, 제안된 블록별 스케일링은 각 레이어와 블록에서 가변적인 수의 연산을 사용한다.
Improving sequence models
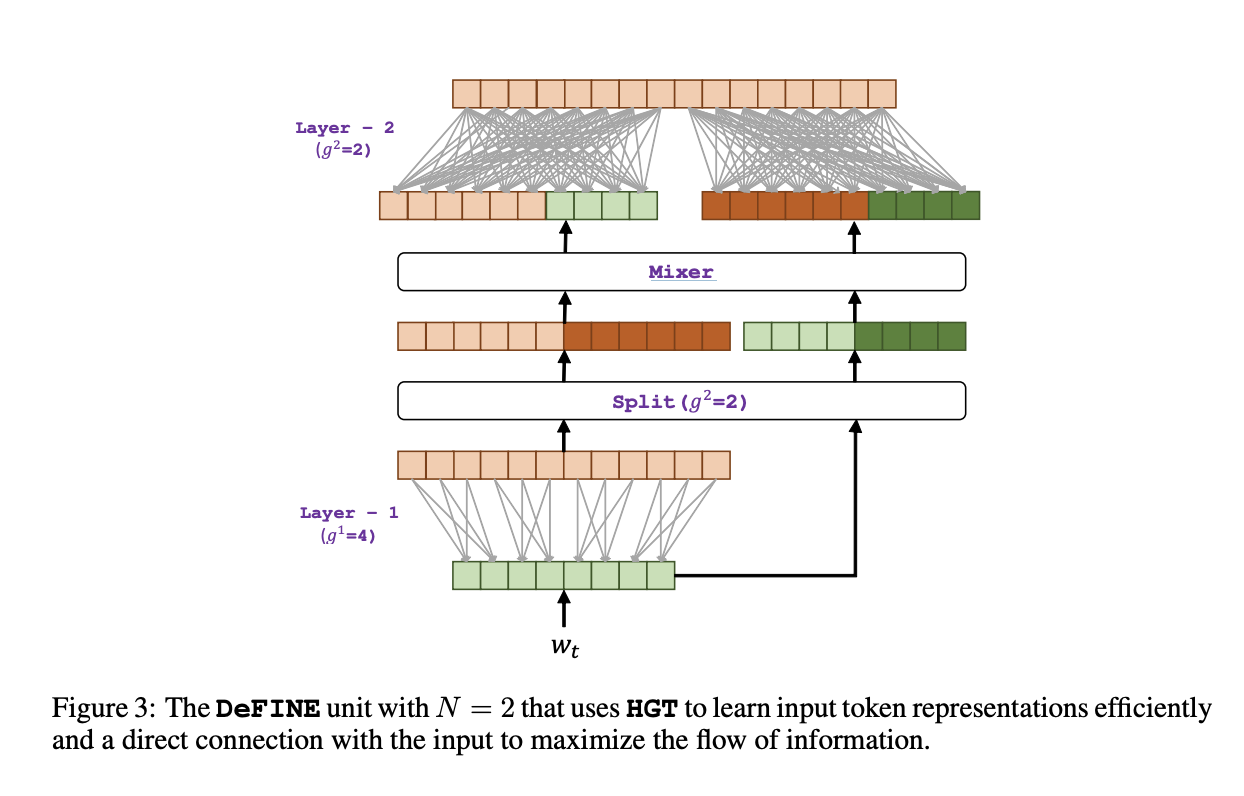
sequence 모델들에 대한 성능 향상 방법에 대하여 설명을 하고있다. 그리고 이전에 제시되었던 DeFINE 모델과 다른 점을 말하고 있는데 여기서는 넓은 표현을 학습하기 위해서 linear 한 변환 과정을 사용한다. 하지만 여기서 DeLight는 더 많은 그룹의 변환과정을 거치지만 적은 파라미털로 이 작업을 수행한다.
3 DELIGHT: DEEP AND LIGHT-WEIGHT TRANSFORMER

먼저 (a) 가 가장 기본적인 transformer의 블록을 표현을 했는데 여기서는 multi-head attention과 feed forward network로 구성이 된다. 먼저 multi-head attention 블록을 보면 input 값에 대하여 Q, K, V 값으로 구분 지어 들어가고 이 값은 다시 dh 값으로 반환된다. 그 이후에는 Attention 블록을 거치고 이것을 concat 하여 다음으로 전달한다. 각각 h 개의 head 가 존재한다면 dh의 dimention은 dm에서 h를 나눈 값이다. dh = dm/h 그리고 FFN 은 이제 2개의 linear layer로 구성이 되며 input 값을 차원을 줄여 전달했다가 이후에는 차원을 늘려 반환한다. 여기서 차원을 줄이는 비율을 깊이의 따라 결정된다. 이렇게 transformer 블록은 여러 단계를 순차적으로 쌓아서 진행된다.
DeLight 블럭에서는 이 방식에서 single-head attention 방식과 light-weight FFN 방식을 통해서 조금 더 가볍게 구조를 만들었다. 그리고 attention 차원을 깊이와 너비에서 분리시켜서 일정하게 쌓는 게 아니라 bolck-wise scaling으로 효과적으로 학습하게 하였다.
3.1 DELIGHT TRANSFORMATION
DeLight 구조에서 dm 차원에서 d0 차원으로 줄이는 방식이 (d) 사진으로 설명되어 있다. 확장 및 축소 단계 동안, DeLighT 변환은 그룹 선형 변환 (GLTs)을 사용한다. 이는 입력의 특정 부분에서 출력을 유도하여 지역 표현을 학습하며 선형 변환보다 효율적이다. 또한 여기서는 convolutional 방식과 같이 channel의 shuffling을 다른 그룹들끼리 linear transformation으로 진행한다.
일반적인 방식은 input 하는 차원을 늘려서 성능을 높이는 방식을 사용한다. 하지만 dm 차원을 늘린다면 작업수가 일반적인 transformer에서는 늘어난다. 하지만 반대로 DeLight는 차원을 늘리고 줄이는 부분이 있기 때문에 input의 차원을 늘려야 한다. 그래서 적은 양의 연산으로는 성능을 내기 어렵다.
공식적으로 DeLight 는 5가지 파라미터로 컨트롤이 가능하다.
1) GLT layer 를 지정하는 N
2) width multiplier Wm
3) input dimension dm
4) output dimensions do
5) maximum groups g_max in a GLT
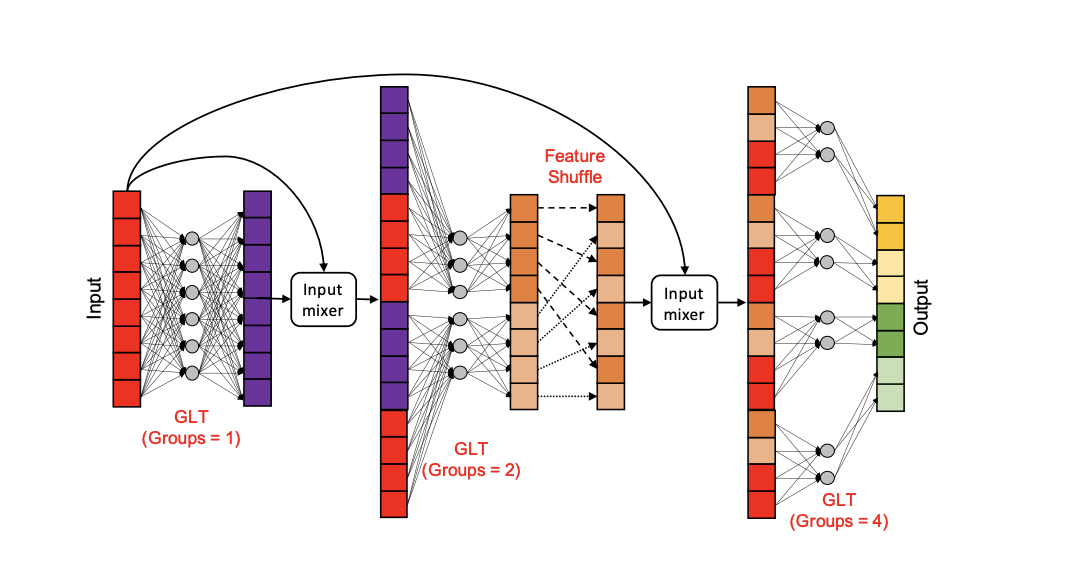
DeLight transformation 에 대하여 설명을 해보겠다. 먼저 전체 GLT 전체 layer N에서 ⎡N/2⎤ 개의 layer들을 모두 차원을 줄이는 layer로 사용한다.
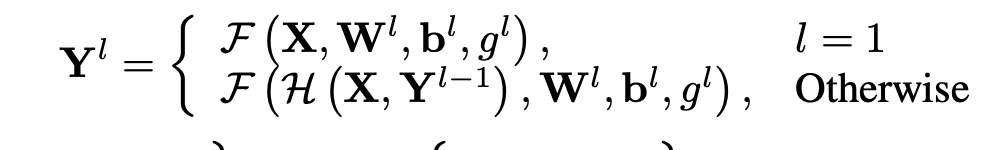
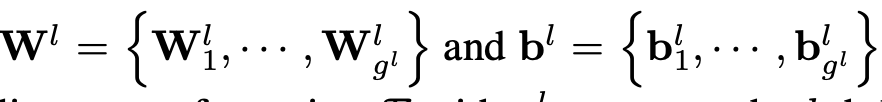
여기서 Input 을 X라고 한다면 l을 진행되고 있는 layer라고 칭한다 그리고 W, b는 각각 학습이 가능한 weight와 bias 들이다. 이렇게 식을 본다면 첫 번째 layer가 아니면 H() 함수의 값이 들어오는데 여기서는 초기의 input 값 X와 이전 layer의 output 값인 Y^l-1 값을 받아서 이전값은 shullfes를 해주고 처음 초기값 X와 mixer connection을 해준다. 이방식은 gradient vanishing 현상을 막기 위해서 추가한 것이다.
아래의 식을 보면 이제 각 layer 마나 group을 지정하는 방식이 나오는데 차원을 확장하는 부분에서는 위의 식을 따르며 그리고 차원을 줄이는 부분에서는 이전 layer의 g 값을 따르도록 되어있다.
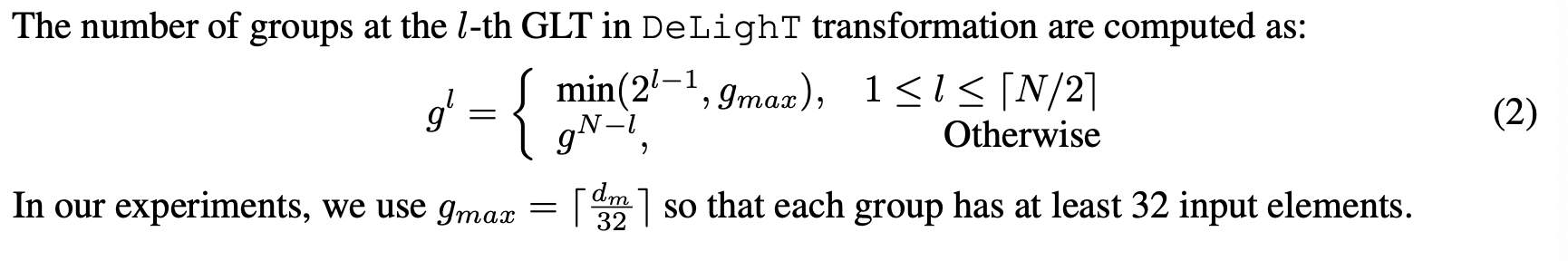
이 GLT 방식의 핵심 요소는 shuffle을 통해서 feature를 global 한 정보를 잘 분산되게 분포를 시키고 mixer를 통해서 vanishing 문제와 local에 대한 정보를 담도록 하였다. 그래서 multi-head attention처럼의 성능이 single-head에서도 나온다고 설명한다.
3.2 DELIGHT
DeLighT layer and single-head attention
DeLighT 구조에서는 먼저 기존의 input 차원보다 줄이는 방식을 사용하여 do 차원의 데이터를 사용한다. 그래서 여기 데이터는 연산량이 기존의 O(dm n^2)에서 O(do n^2)로 줄어들게 된다. 구조상으로 do의 차원이 더 작음으로 연산량이 더 작으면 2배가 차이 난다면 연산량도 2배로 차이가 나게 된다.
Light-weight FFN
여기서는 이미 앞부분에서 DeLight transformation을 토앻서 global 한 feature를 추출을 하였기 때문에 여기서는 차원을 줄여서 사용한다. 그래서 이 부분에서는 기존 방식보다 연산하는 파마리터의 양이 줄어든다
.
Block depth
기존 방식에서 transformer는 깊이가 4 정도로 구성되어 있는데 DeLight에서는 4개뿐만 아니라 GLT 구조까지 포함해서 전분 N+4 개의 블록으로 구성이 된다.
3.3 BLOCK-WISE SCALING
기본적인 성능을 높이기 위해서는 모델의 차원을 늘리거나 모델의 블록을 더 쌓거나 아니면 둘 다 활용하거나 할 수 있다. 하지만 작은 데이터셋의 경우 같은 상황에서는 성능 향상이 많이 일어나지 않는다. 이 방식은 단순히 불필요한 파라미터의 학습만을 야기하게 된다. 그래서 단순히 같은 크기로 늘리는 게 아닐 레벨에 따라서 파라미터 양을 조절하여 연산양을 조절한다.
Scaling the DeLighT block
DeLight 블록은 깊고 넚은 표현을 GLT 방식으로 컨트롤한다. 그리고 이것은 GLT layer N과 Wm에 의하여 결정된다. 이렇게 input, output 차원과 각가 별개로 학습할 수 있는 파라미터를 늘리는 게 가능하다. 그래서 DeLight 모델에서는 input에서는 Input 값 근처에서는 작게 output 근처에서는 크게 모델을 구성한다.
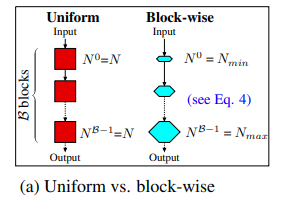
그림과 같이 minimum N min과 maximum N max numver를 GLT의 구성요소로 사용한다.
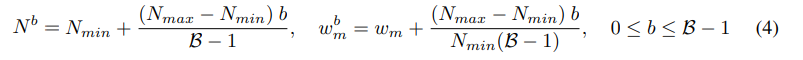
B는 DeLight 블록을 말고 b 는 블럭 안에서의 GLT layer 중에서 숫자를 말한다.



