
운동하는 공대생
[교육봉사] 손글씨 분류하기 실습 본문
1. CNN(Convolution Neural Network)
합성곱 신경망(CNN, Convolutional Neural Network)은 컴퓨터 비전 작업을 위해 특히 유용한 딥 러닝 모델 중 하나입니다. 아래에서 CNN의 기본 개념과 작동 방식을 설명하겠습니다.
1. 컨볼루션(Convolution): CNN은 주로 이미지 처리에 사용되며, 이러한 이미지는 2D 그리드로 표현됩니다. 컨볼루션은 이러한 이미지에 필터(또는 커널)를 적용하여 특징을 추출하는 과정입니다. 각 필터는 입력 이미지에서 작은 영역을 선택하고 가중치를 적용하여 출력 특징 맵을 생성 합니다. 필터를 이동하면서 이미지 전체를 훑어가면서 특징을 추출합니다.
2. 필터(커널): 필터는 작은 가중치 행렬로, 입력 이미지에서 특정한 특징을 감지하는 역할을 합니다. 예를 들어, 가장자리 검출을 위한 필터나 텍스트를 감지하기 위한 필터 등이 있습니다.
3. 풀링(Pooling): 컨볼루션 레이어 다음에는 풀링 레이어가 주로 옵니다. 풀링은 출력 특징 맵의 크기를 줄이고 계산량을 감소시키는 역할을 합니다. 가장 일반적인 풀링 연산은 최대 풀링(max pooling)이며, 주어진 영역에서 가장 큰 값을 선택하여 출력합니다.
4. 완전 연결 레이어(Fully Connected Layer): 컨볼루션 레이어와 풀링 레이어를 통해 추출된 특징들은 최종적으로 완전 연결 레이어에 전달됩니다. 이 레이어는 추출된 특징을 사용하여 입력 데이터를 클래스 레이블로 분류하는 데 사용됩니다.
5. 학습 및 역전파(Training and Backpropagation): CNN은 역전파 알고리즘을 사용하여 가중치를 조정하고 학습합니다. 손실 함수를 정의하고, 실제 클래스와 예측 클래스 간의 오차를 최소화하도록 가중치를 업데이트합니다. 이러한 과정을 반복하여 모델을 훈련시킵니다.
6. 드롭아웃(Dropout): 드롭아웃은 과적합을 방지하기 위한 기술 중 하나로, 훈련 중에 랜덤하게 일부 뉴런을 비활성화하여 모델을 더 견고하게 만듭니다.
CNN은 이미지 분류, 객체 감지, 얼굴 인식, 자연어 처리 등 다양한 컴퓨터 비전 및 딥 러닝 작업에 사용됩니다. 특히 이미지 분류 작업에서 우수한 성능을 보이며, 이미지의 공간적인 특징을 잘 이해하는 모델로 알려져 있습니다.

실습
import cv2
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.autograd import Variable
from torch.optim.lr_scheduler import StepLR
# Define your neural network architecture with dropout layers
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 64, kernel_size=5)
self.fc1 = nn.Linear(1024, 128)
self.fc2 = nn.Linear(128, 10)
self.dropout = nn.Dropout(0.5) # Add dropout with a probability of 0.5
def forward(self, x):
x = torch.relu(torch.max_pool2d(self.conv1(x), 2))
x = torch.relu(torch.max_pool2d(self.conv2(x), 2))
x = x.view(x.size(0), -1)
x = torch.relu(self.fc1(x))
x = self.dropout(x) # Apply dropout here
x = self.fc2(x)
return2. Data
1. 데이터셋 형식 (MNIST):
- MNIST는 손으로 쓴 숫자(0에서 9까지의 숫자)로 구성된 대표적인 컴퓨터 비전 데이터셋입니다. 이 데이터셋은 28x28 픽셀 크기의 흑백 이미지로 이루어져 있으며, 각 이미지는 하나의 숫자를 나타냅니다. 따라서 MNIST 데이터셋은 숫자 분류 작업에 사용하기에 이상적입니다.
2. 데이터 전처리:
- tranorms.Compose를 사용하여 데이터 전처리 파이프라인을 정의합니다. 데이터 전처리는 입력 데이터를 모델에 맞게 변환하는 과정으로, 일반적으로 다음과 같은 단계로 수행됩니다:
- tranorms.RandomRotation(10): 이미지를 최대 10도까지 랜덤하게 회전시킵니다. 이렇게 하면 데이터의 다양성이 증가하고 모델이 회전에 강인해집니다.
- tranorms.RandomAff∈e(0, : 이미지를 랜덤 하게 수평 및 수직으로 최대 10% 이동시킵니다. 이것은 데이터에 대한 변형을 적용하여 모델을 더 견고하게 만듭니다.
- transforms.ToTensor(): 이미지를 PyTorch 텐서로 변환합니다. 신경망은 텐서 형식의 입력을 예상하므로 이미지를 텐서로 변환해야 합니다.
- transforms.Normalize((0.5,), (0.5,)): 이미지의 각 픽셀 값을 정규화합니다. 이는 입력 데이터의 평균을 0.5로 만들고 표준 편차를 0.5로 만들어서 모델 학습을 안정화시키고 수렴 속도를 향상합니다.
3. 데이터 로더 설정:
- torch.utils.data.DataLoader를 사용하여 전처리된 데이터셋을 미니배치로 나누고, 셔플링하여 학습에 사용할 수 있도록 설정합니다.
- batch_size=64: 각 미니배치의 크기를 64로 설정합니다. 한 번에 64개의 이미지를 처리하여 계산 효율성을 높이고 미니배치 경사 하강법을 사용합니다.
- shuffle=True: 데이터를 에포크마다 섞어서 모델에 무작위성을 주고 과적합을 방지합니다.
3. What is batch?
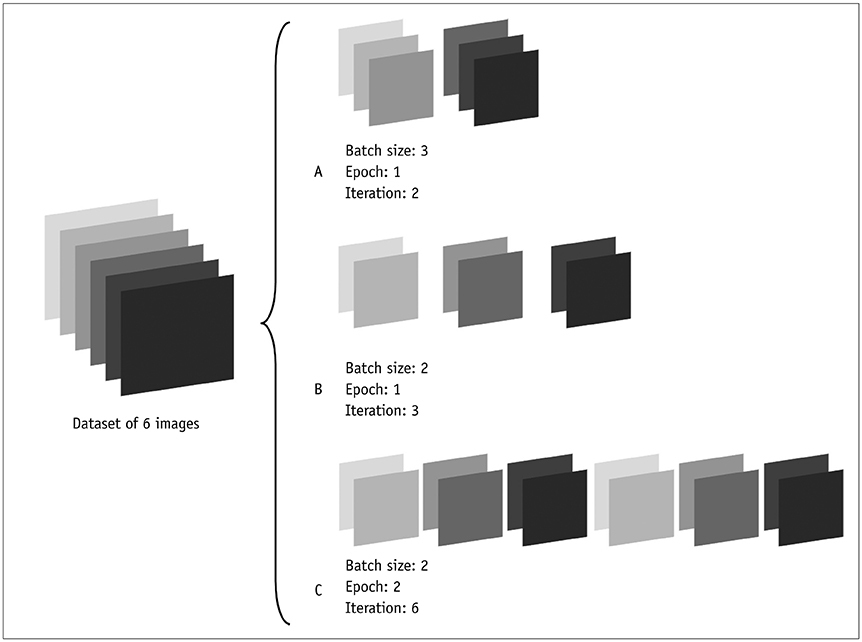
=> 데이터를 여러개로 쪼개서 모델을 학습하는 기술
뭐가 좋아?
과적합을 방지하고 데이터에 대학 학습 속도를 빠르게 증가시킨다.
실습
# Data preprocessing and data loader setup with data augmentation
transform = transforms.Compose([
transforms.RandomRotation(10), # Randomly rotate the image by up to 10 degrees
transforms.RandomAffine(0, translate=(0.1, 0.1)), # Randomly translate the image
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
trainset = torchvision.datasets.MNIST(root='MNIST/raw/train-images-idx3-ubyte', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
4. Train
1. 손실함수 - CrossEntropyLoss(크로스 엔트로피 손실):
- nn.CrossEntropyLoss는 다중 클래스 분류 문제를 다룰 때 주로 사용되는 손실 함수입니다.
- 크로스 엔트로피 손실은 실제 클래스와 예측 클래스 간의 오차를 측정합니다. 이 손실은 모델이 예측한 클래스 확률 분포와 실제 클래스의 원핫 인코딩 간의 차이를 계산하여 손실 값을 반환합니다.
- 모델이 클래스 간의 확률 분포를 조절하고, 예측을 향상시키도록 돕는 중요한 요소 중 하나입니다.
2. 최적화 함수 - SGD(확률적 경사 하강법):
- optim.SGD는 확률적 경사 하강법 알고리즘을 구현한 PyTorch의 최적화(optimizer) 클래스입니다.
- 확률적 경사 하강법은 가중치 업데이트를 위해 각 미니배치의 그래디언트(기울기)를 사용하는 최적화 알고리즘입니다.
- lr 매개변수를 통해 학습률(learning rate)을 조절할 수 있으며, momentum 매개변수를 사용하여 관성을 추가할 수 있습니다. 관성은 이전 그래디언트의 영향을 고려하여 가중치 업데이트를 수행합니다.
3. 스케줄러 - StepLR(학습률 스케줄러):
- `torch.optihttp://m.lr_scheduler.StepLR는 학습률(learning rate)을 조절하는 스케줄러입니다. - 주로 학습률을 에포크(epoch)별로 조절하는 데 사용됩니다. 예를 들어, 일정한 에포크 간격으로 학습률을 감소시키는 데 유용합니다. - step_size 매개변수는 학습률을 조절할 단계 크기를 나타내며, gamma 매개변수는 학습률을 감소시키는 비율을 나타냅니다. step_size에 도달할 때마다 학습률은 gamma`를 곱하여 감소합니다.
이러한 손실 함수, 최적화 알고리즘 및 학습률 스케줄러는 모델 학습을 효과적으로 조정하고 최적의 가중치를 찾도록 도와줍니다. 이들을 적절하게 조절하면 모델의 수렴 속도와 성능을 향상시킬 수 있습니다.
# Initialize the model, loss function, and optimizer
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# Learning rate scheduling
scheduler = StepLR(optimizer, step_size=3, gamma=0.1)
# Training loop with dropout and learning rate scheduling
for epoch in range(5):
scheduler.step() # Update the learning rate at the beginning of each epoch
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
inputs, labels = Variable(inputs), Variable(labels)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(trainloader)}')
print('Finished Training')
# Save the trained model
torch.save(model.state_dict(), 'mnist_model.pth')
5. 예측 진행
import cv2
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.autograd import Variable
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 64, kernel_size=5)
self.fc1 = nn.Linear(1024, 128)
self.fc2 = nn.Linear(128, 10)
self.dropout = nn.Dropout(0.5) # Add dropout with a probability of 0.5
def forward(self, x):
x = torch.relu(torch.max_pool2d(self.conv1(x), 2))
x = torch.relu(torch.max_pool2d(self.conv2(x), 2))
x = x.view(x.size(0), -1)
x = torch.relu(self.fc1(x))
x = self.dropout(x) # Apply dropout here
x = self.fc2(x)
return x
model = Net()
# Load the trained model's state dictionary
model.load_state_dict(torch.load('mnist_model.pth'))
# Set the model to evaluation mode
model.eval()
import cv2
import torch
import torchvision.transforms as transforms
from torch.autograd import Variable
import matplotlib.pyplot as plt
# Load and resize your image to 28x28
image_path = '7.jpeg'
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
image = cv2.resize(image, (28, 28))
# Display the resized image
plt.imshow(image, cmap='gray')
plt.axis('off') # Hide the axis
plt.show()
image_path = '5.jpeg'
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
image = cv2.resize(image, (28, 28))
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
image = transform(image).unsqueeze(0) # Add batch dimension
# Use the trained model for prediction
with torch.no_grad():
outputs = model(image)
print(outputs)
_, predicted = torch.max(outputs, 1)
print(f'Predicted Class: {predicted.item()}')